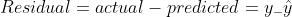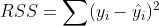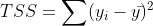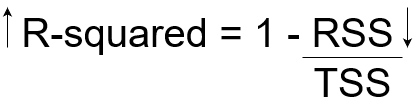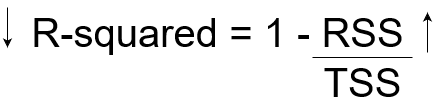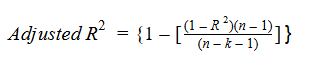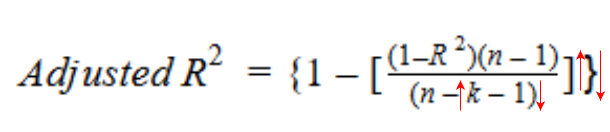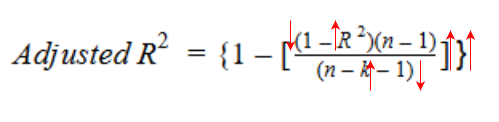We use cookies essential for this site to function well. Please click to help us improve its usefulness with additional cookies. Learn about our use of cookies in our Privacy Policy & Cookies Policy.
Show details
Powered By
Cookies
This site uses cookies to ensure that you get the best experience possible. To learn more about how we use cookies, please refer to our Privacy Policy & Cookies Policy.
brahmaid
It is needed for personalizing the website.
csrftoken
This cookie is used to prevent Cross-site request forgery (often abbreviated as CSRF) attacks of the website
Identityid
Preserves the login/logout state of users across the whole site.
sessionid
Preserves users' states across page requests.
g_state
Google One-Tap login adds this g_state cookie to set the user status on how they interact with the One-Tap modal.
MUID
Used by Microsoft Clarity, to store and track visits across websites.
_clck
Used by Microsoft Clarity, Persists the Clarity User ID and preferences, unique to that site, on the browser. This ensures that behavior in subsequent visits to the same site will be attributed to the same user ID.
_clsk
Used by Microsoft Clarity, Connects multiple page views by a user into a single Clarity session recording.
SRM_I
Collects user data is specifically adapted to the user or device. The user can also be followed outside of the loaded website, creating a picture of the visitor's behavior.
SM
Use to measure the use of the website for internal analytics
CLID
The cookie is set by embedded Microsoft Clarity scripts. The purpose of this cookie is for heatmap and session recording.
SRM_B
Collected user data is specifically adapted to the user or device. The user can also be followed outside of the loaded website, creating a picture of the visitor's behavior.
_gid
This cookie is installed by Google Analytics. The cookie is used to store information of how visitors use a website and helps in creating an analytics report of how the website is doing. The data collected includes the number of visitors, the source where they have come from, and the pages visited in an anonymous form.
_ga_#
Used by Google Analytics, to store and count pageviews.
_gat_#
Used by Google Analytics to collect data on the number of times a user has visited the website as well as dates for the first and most recent visit.
collect
Used to send data to Google Analytics about the visitor's device and behavior. Tracks the visitor across devices and marketing channels.
AEC
cookies ensure that requests within a browsing session are made by the user, and not by other sites.
G_ENABLED_IDPS
use the cookie when customers want to make a referral from their gmail contacts; it helps auth the gmail account.
test_cookie
This cookie is set by DoubleClick (which is owned by Google) to determine if the website visitor's browser supports cookies.
_we_us
this is used to send push notification using webengage.
WebKlipperAuth
used by webenage to track auth of webenagage.
ln_or
Linkedin sets this cookie to registers statistical data on users' behavior on the website for internal analytics.
JSESSIONID
Use to maintain an anonymous user session by the server.
li_rm
Used as part of the LinkedIn Remember Me feature and is set when a user clicks Remember Me on the device to make it easier for him or her to sign in to that device.
AnalyticsSyncHistory
Used to store information about the time a sync with the lms_analytics cookie took place for users in the Designated Countries.
lms_analytics
Used to store information about the time a sync with the AnalyticsSyncHistory cookie took place for users in the Designated Countries.
liap
Cookie used for Sign-in with Linkedin and/or to allow for the Linkedin follow feature.
visit
allow for the Linkedin follow feature.
li_at
often used to identify you, including your name, interests, and previous activity.
s_plt
Tracks the time that the previous page took to load
lang
Used to remember a user's language setting to ensure LinkedIn.com displays in the language selected by the user in their settings
s_tp
Tracks percent of page viewed
AMCV_14215E3D5995C57C0A495C55%40AdobeOrg
Indicates the start of a session for Adobe Experience Cloud
s_pltp
Provides page name value (URL) for use by Adobe Analytics
s_tslv
Used to retain and fetch time since last visit in Adobe Analytics
li_theme
Remembers a user's display preference/theme setting
li_theme_set
Remembers which users have updated their display / theme preferences
We do not use cookies of this type.
_gcl_au
Used by Google Adsense, to store and track conversions.
SID
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
SAPISID
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
__Secure-#
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
APISID
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
SSID
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
HSID
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
DV
These cookies are used for the purpose of targeted advertising.
NID
These cookies are used for the purpose of targeted advertising.
1P_JAR
These cookies are used to gather website statistics, and track conversion rates.
OTZ
Aggregate analysis of website visitors
_fbp
This cookie is set by Facebook to deliver advertisements when they are on Facebook or a digital platform powered by Facebook advertising after visiting this website.
fr
Contains a unique browser and user ID, used for targeted advertising.
bscookie
Used by LinkedIn to track the use of embedded services.
lidc
Used by LinkedIn for tracking the use of embedded services.
bcookie
Used by LinkedIn to track the use of embedded services.
aam_uuid
Use these cookies to assign a unique ID when users visit a website.
UserMatchHistory
These cookies are set by LinkedIn for advertising purposes, including: tracking visitors so that more relevant ads can be presented, allowing users to use the 'Apply with LinkedIn' or the 'Sign-in with LinkedIn' functions, collecting information about how visitors use the site, etc.
li_sugr
Used to make a probabilistic match of a user's identity outside the Designated Countries
MR
Used to collect information for analytics purposes.
ANONCHK
Used to store session ID for a users session to ensure that clicks from adverts on the Bing search engine are verified for reporting purposes and for personalisation
We do not use cookies of this type.
Cookie declaration last updated on 24/03/2023 by Analytics Vidhya.
Cookies are small text files that can be used by websites to make a user's experience more efficient. The law states that we can store cookies on your device if they are strictly necessary for the operation of this site. For all other types of cookies, we need your permission. This site uses different types of cookies. Some cookies are placed by third-party services that appear on our pages. Learn more about who we are, how you can contact us, and how we process personal data in our Privacy Policy.
When I started my journey in Data Science, the first algorithm that I explored was Linear Regression. After understanding the concepts of Linear Regression and how the algorithm works, I was really excited to use it and make predictions on a problem statement. I am sure most of you would have done the same. But once we have predicted the values, what is next?
Then comes the tricky part. Once we have built our model, the next step was to evaluate its performance. Needless to say, the task of model evaluation is a pivotal one and highlights the shortcomings of our model. Choosing the most appropriate Evaluation Metric is a crucial task. And, I came across two important metrics: R squared and Adjusted R Squared apart from MAE/ MSE/ RMSE. What is the difference between R2 and Adjusted R2, and when should we use each? Understanding the difference between R2 and Adjusted R2 is crucial for effective model evaluation.
R-squared and Adjusted R-squared Python are two such evaluation metrics that might seem confusing to any data science aspirant initially. Since they both are extremely important to evaluate regression problems, we are going to understand and compare them in-depth. They both have their pros and cons p-values, which we will be discussing in detail in this article of Adjusted R Squared and also you wil get to know about r squared vs adjusted r squared.
Learning Objectives
Understand the concept of R-squared and Adjusted R Squared.
Learn how these metrics evaluate the goodness of fit for regression models.
Grasp the key differences between R-Squared and Adjusted R-squared.
R-squared measures the proportion of the variance in the dependent variable explained by the independent variables in the model.
It ranges from 0 to 1, where 0 indicates that the model does not explain any variability, and one indicates that it explains all the variability.
Higher R-squared values suggest a better fit, but it doesn’t necessarily mean the model is a good predictor in an absolute sense.
Adjusted R-Squared
Adjusted R-squared addresses a limitation of Adjusted R Squared, especially in multiple regression (models with more than one independent variable).
While R-squared tends to increase as more variables are added to the model (even if they don’t improve the model significantly), Adjusted r squared vs adjusted r squared penalizes the addition of unnecessary variables.
It considers the number of predictors in the model and adjusts R-squared accordingly. This adjustment helps to avoid overfitting, providing a more accurate measure of the model’s goodness of fit.
Comparison
R-squared will stay the same when adding more predictors, even if they are not contributing meaningfully. It may give a falsely optimistic view of the model.
Adjusted R-squared is more conservative and will decrease if additional variables do not contribute to the model’s explanatory power.
As a rule of thumb, a higher R-squared or Adjusted r squared vs adjusted r squared is desirable, but it’s crucial to consider the context of the specific analysis and the trade-off between model complexity and explanatory power
Residual Sum of Squares
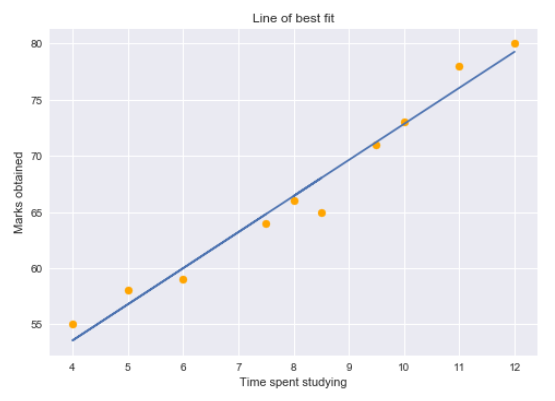
To understand the concepts clearly, we are going to take up a simple regression problem. Here, we are trying to predict the ‘Marks Obtained’ based on the amount of ‘Time Spent Studying,’ with the time spent studying serving as our independent variable and the marks achieved in the test as our dependent or target variable. As we delve into evaluating the goodness of fit for our regression model, it’s essential to consider metrics like the traditional Adjusted R2 squared and its adjusted counterpart, Adjusted R-squared. These metrics will help us gauge how well our model explains the variability in the dependent variable, offering a more comprehensive assessment that considers the potential impact of additional variables.
We can plot a simple regression graph to visualize this data.
The yellow dots represent the data points and the blue line is our predicted regression line. As you can see, our regression model does not perfectly predict all the data points. So how do we evaluate the predictions from the regression line using the data? Well, we could start by determining the residual values for the data points.
Residual for a point in the data is the difference between the actual value and the value predicted by our linear regression model.
Residual plots tell us whether the regression model is the right fit for the data or not. It is actually an assumption of the regression model that there is no trend in residual plots. To study the assumptions of linear regression in detail, I suggest going through this great article!
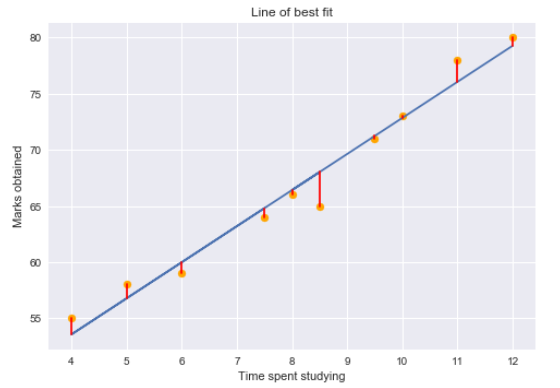
Using the residual values, we can determine the sum of squares of the residuals also known as Residual sum of squares or RSS.
The lower the value of RSS, the better is the model predictions. Or we can say that – a regression line is a line of best fit if it minimizes the RSS value. But there is a flaw in this – RSS is a scale variant statistic. Since RSS is the sum of the squared difference between the actual and predicted value, the value depends on the scale of the target variable.
Example
Consider your target variable is the revenue generated by selling a product. The residuals would depend on the scale of this target. If the revenue scale was taken in “Hundreds of Rupees” (i.e. target would be 1, 2, 3, etc.) then we might get an RSS of about 0.54 (hypothetically speaking).
But if the revenue target variable was taken in “Rupees” (i.e. target would be 100, 200, 300, etc.), then we might get a larger RSS as 5400. Even though the data does not change, the value of RSS varies according to the scale of the target. This makes it difficult to judge what might be a good RSS value.
So, can we come up with a better statistic that is scale-invariant? This is where r squared vs adjusted r squared comes into the picture.
Understanding R-squared statistic
R-squared statistic or coefficient of determination is a scale invariant statistic that gives the proportion of variation in target variable explained by the linear regression model.
This might seem a little complicated, so let me break this down here. In order to determine the proportion of target variation explained by the model, we need to first determine the following-
Total Sum of Squares
Total variation in target variable is the sum of squares of the difference between the actual values and their mean.
TSS or Total sum of squares gives the total variation in Y. We can see that it is very similar to the variance of Y. While the variance is the average of the squared sums of difference between actual values and data points, TSS is the total of the squared sums.
Now that we know the total variation in the target variable, how do we determine the proportion of this variation explained by our model? We go back to RSS.
Residual Sum of Squares
As we discussed before, RSS gives us the total square of the distance of actual points from the regression line. But if we focus on a single residual, we can say that it is the distance that is not captured by the regression line. Therefore, RSS as a whole gives us the variation in the target variable that is not explained by our model.
Calculate R-Squared
Now, if TSS gives us the total variation in Y, and RSS gives us the variation in Y not explained by X, then TSS-RSS gives us the variation in Y that is explained by our model! We can simply divide this value by TSS to get the proportion of variation in Y that is explained by the model. And this our R-squared statistic!
R-squared = (TSS-RSS)/TSS
= Explained variation/ Total variation
= 1 – Unexplained variation/ Total variation
So r squared vs adjusted r2 squared gives the degree of variability in the target variable that is explained by the model or the independent variables. If this value is 0.7, then it means that the independent variables explain 70% of the variation in the target variable.
R-squared value always lies between 0 and 1. A higher R-squared value indicates a higher amount of variability being explained by our model and vice-versa.
If we had a really low RSS value, it would mean that the regression line was very close to the actual points. This means the independent variables explain the majority of variation in the target variable. In such a case, we would have a really high R-squared value.
On the contrary, if we had a really high RSS value, it would mean that the regression line was far away from the actual points. Thus, independent variables fail to explain the majority of variation in the target variable. This would give us a really low R-squared value.
So, this explains why the R-squared value gives us the variation in the target variable given by the variation in independent variables.
Problems with R-squared Statistic
The R-squared statistic isn’t perfect. In fact, it suffers from a major flaw. Its value never decreases no matter the number of variables we add to our regression model. That is, even if we are adding redundant variables to the data, the value of R-squared does not decrease. It either remains the same or increases with the addition of new independent variables. This clearly does not make sense because some of the independent variables might not be useful in determining the target variable. Adjusted R-squared deals with this issue.
What is Adjusted R-squared?
Adjusted R Squared is a statistical measure used to evaluate the goodness of fit of a regression model. It provides insights into how well the model explains the variability in the data.
Unlike the standard R-squared, which simply tells you the proportion of variance explained by the model, Adjusted R-squared takes into account the number of predictors (independent variables) in the model.
The advantage of Adjusted r squared vs adjusted r squared is that it penalizes the inclusion of unnecessary variables. This means that as you add more predictors to the model, the Adjusted R-squared value will only increase if the new variables significantly improve the model’s performance.
In summary, a higher Adjusted R-squared value indicates that more of the variation in the dependent variable is explained by the model, while also considering the model’s simplicity. It’s a valuable tool for model selection, helping you strike a balance between explanatory power and complexity.
Adjusted R-squared statistic
The Adjusted R-squared takes into account the number of independent variables used for predicting the target variable. In doing so, we can determine whether adding new variables to the model actually increases the model fit.
Let’s have a look at the formula for adjusted R-squared to better understand its working.
Here,
n represents the number of data points in our dataset
k represents the number of independent variables, and
R represents the R-squared values determined by the model.
So, if R-squared does not increase significantly on the addition of a new independent variable, then the value of Adjusted R-squared will actually decrease.
On the other hand, if on adding the new independent variable we see a significant increase in R-squared value, then the Adjusted R-squared value will also increase.
We can see the difference between R-squared and Adjusted R-squared values if we add a random independent variable to our model.
As you can see, adding a random independent variable did not help in explaining the variation in the target variable. Our R-squared value remains the same. Thus, giving us a false indication that this variable might be helpful in predicting the output. However, the Adjusted R-squared value decreased which indicated that this new variable is actually not capturing the trend in the target variable.
Clearly, it is better to use Adjusted R-squared when there are multiple variables in the regression model. This would allow us to compare models with differing numbers of independent variables.
What is the difference between adjusted R-squared and R-square?
Regression analysis uses both adjusted R-squared and R-squared as metrics to evaluate how well a model fits the data. Their approaches to accounting for the quantity of variables in the model, however, vary.
R-squared: This is a more straightforward statistic that shows how much of the variance in the response variable—what you’re attempting to predict—is accounted for by the independent variables—the elements you’re utilizing to form your forecast. A higher number on the scale of 0 to 1 denotes a better fit. As the sample size increases, the reliability of the R-squared value also improves, providing a clearer picture of the model’s performance.
Adjusted R-squared penalizes the model for superfluous complexity, which is a step up from R-squared. Why this matters is as follows:
Even if the additional variables don’t actually improve the model’s R-squared, adding more to it will generally enhance the predictive capacity of linear models. This may result in overfitting, a situation in which the model identifies random noise in the data instead of the underlying patterns.
This is made up for by adjusted R-squared, which takes the number of predictor variables in the model into account. In essence, it promotes models that adequately explain the data with fewer variables and discourages models that haphazardly add more. Because of this, adjusted R-squared may be less than R-squared, but it still gives a more realistic impression of the model’s ability to generalize to new data. As the sample size increases, adjusted R-squared provides a more reliable metric for evaluating the model’s performance.
Conclusion
In this article, comparing R-squared and Adjusted R-squared provides insights into model fit and complexity. Residual Sum of Squares gauges the model’s accuracy, while understanding R-squared illuminates explained variance. Despite its utility, R-squared has limitations, addressed by the more nuanced Adjusted R-squared. Both metrics refine our assessment of regression models
Hopefully, this has given you a better understanding of things. You can now determine prudently which independent variables are helpful in predicting the output of your regression problem.
Key Takeaways
R-squared measures the proportion of variance explained by independent variables.
Adjusted R-squared penalizes addition of unnecessary variables, avoiding overfitting.
Adjusted R2-squared provides a more accurate measure for models with multiple predictors.
To know more about other evaluation metrics, I suggest going through the following great resources:
A. R-squared indicates the proportion of the variance in the dependent variable that is predictable from the independent variables.
Q2. What does SSR represent in regression analysis?
A. SSR (Sum of Squared Residuals) represents the total deviation of the predicted values from the actual values, indicating the model’s error.
Q3. What does R^2 mean in correlation?
A. In correlation, R^2 signifies the strength and direction of the linear relationship between two variables, showing how well one variable predicts the other.
Q4. What is the difference between R-squared and adjusted R-squared?
A. R-squared measures the proportion of variance explained by the model, while adjusted R-squared adjusts for the number of predictors, providing a more accurate measure for models with multiple variables.