This article was published as a part of the Data Science Blogathon
In this article, we will learn how to classify images based on fine details of images using a stacked pre-trained model to get maximum accuracy in TensorFlow.
Introduction
Hey folks, I hope you have done some image classification using pre-trained TensorFlow or TensorFlowor other CNN pre-trained models and might have some idea about how we classify images, but when it comes to classifying finely detailed objects (dog breed, cat breed, leaves diseases) this method doesn’t give us a good result, in this case, we would prefer model stacking to capture most of the details. Let’s get straight to the technicalities of it.
In our dataset, we have 120 dog breeds and we will have to classify them using a stacked pre-trained model (TensorFlow, Densenet121) which is trained on Imagenet. We will stack bottleneck features extracted by these models for greater accuracy that will depend on the models we are stacking together.
How do Stacked Pretrined Models work?
When you work on a classification problem you tend to use a classifier that majorly focuses on the max pooled features that mean it does take fine or small objects into account while training. This is why we use stacked models that help to easily classify the images based on both highlighted and fine object details.
For creating a stacked model you need to use two or more classification architectures like Resnet, Vgg, Densenet, etc. These classifiers take an image as input and generate feature matrices based on their architecture. Normally each classifier goes ahead with the following stages in order to create a feature vector:
1. Convolution: It is the process of generating feature maps that depict the different image-specific features like edges, sharpness, etc of an image.
2. Max Pooling: In this process highlighted features are extracted from the feature maps that are generating using the convolution process.
3. Flattening: In this process, final feature maps are converted into a vector of features.
after getting the feature vectors from different models we stack them together in order to come up with a feature matrix that is then used as an input for the final Neural Network model whose work is to classify these matrices into final classes of data.
Now that you know how a stacked model works let’s design a stacked model using Vgg16 and Resnet architectures.
Designing Stacked Pretrained Models
Before moving ahead let’s have a look at how we stack models to get bottleneck features.
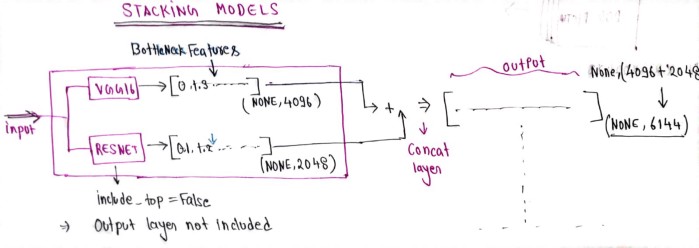
in the above image, you can clearly see that we have two classifier models VGG16 and Resnet which are used as feature extractors and then stacked together to come up with a final set of features used for classification.
Let’s write the code to generate the following architecture:
from keras.applications.resnet_v2 import ResNet50V2 , preprocess_input as resnet_preprocess
from keras.applications.densenet import DenseNet121, preprocess_input as densenet_preprocess
from keras.layers.merge import concatenateinput_shape = (331,331,3)
input_layer = Input(shape=input_shape)#first feature extractor
preprocessor_resnet = Lambda(resnet_preprocess)(input_layer)
resnet50v2 = ResNet50V2(weights = 'imagenet',
include_top = False,input_shape = input_shape,pooling ='avg')(preprocessor_resnet)preprocessor_densenet = Lambda(densenet_preprocess)(input_layer)
densenet = DenseNet121(weights = 'imagenet',
include_top = False,input_shape = input_shape,pooling ='avg')(preprocessor_densenet)merge = concatenate([resnet50v2,densenet])
stacked_model = Model(inputs = input_layer, outputs = merge)
stacked_model.summary()
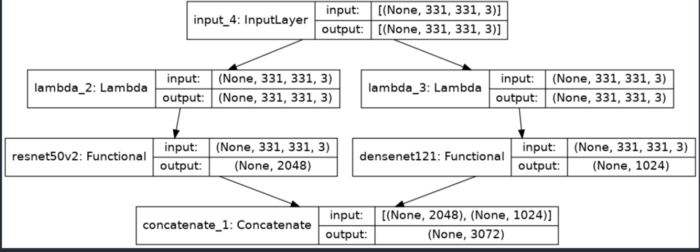
Here we have stacked two models (Densenet121, and resnet50V2) both have include_top = False means we are only extracting bottleneck features and then using concatenate layer for merging them.
Building Dog Breed Classifier Using Stacked Pretrained Models
Now that you know how you can create a stacked model we can go ahead and start creating a Dog Breed Classifier.
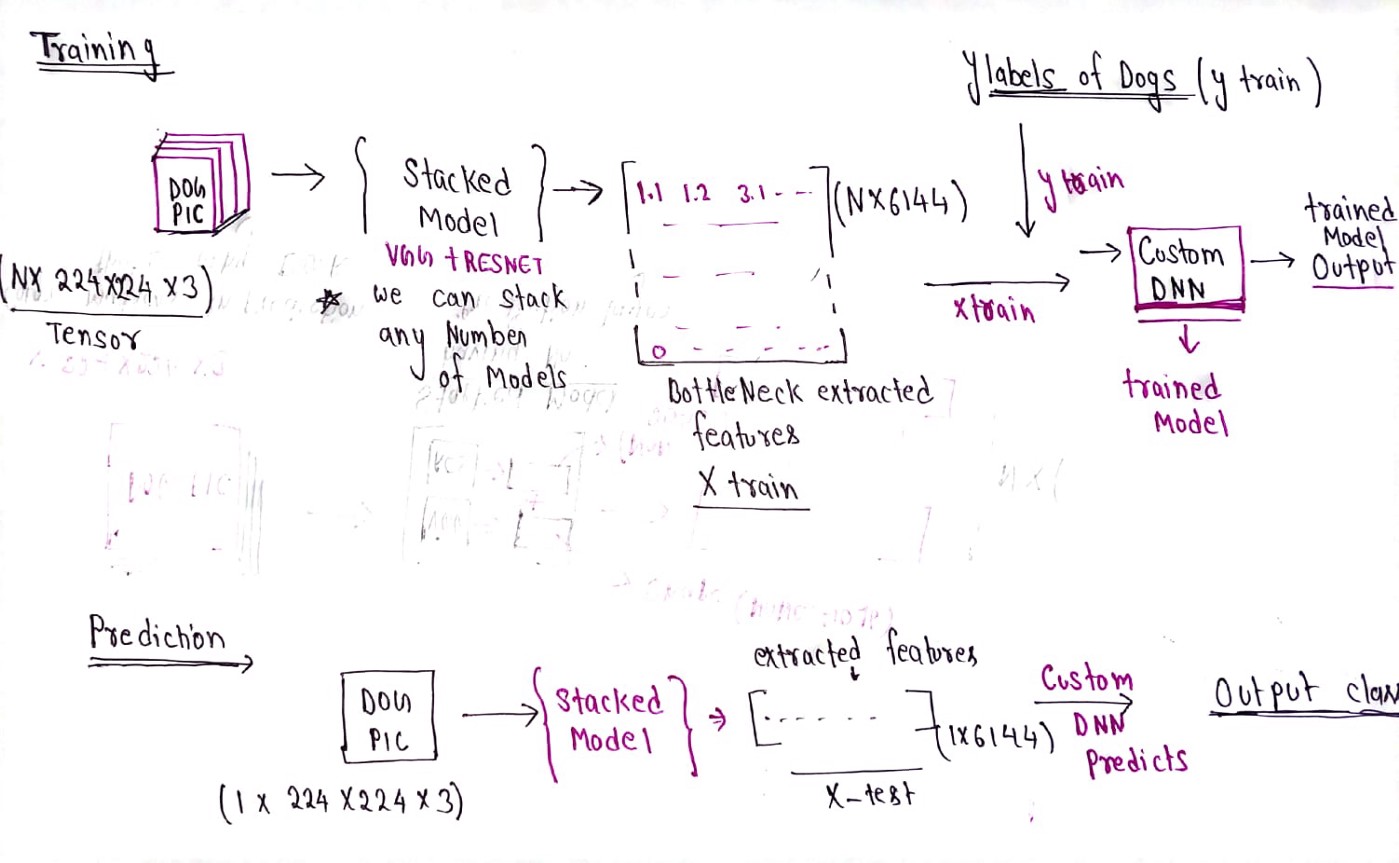
The above diagram shows the workflow of training and inferencing the classifier. We will train a stacked model on our images which will generate a feature matrix which would then be used as input features by another Neural Network to classify the Dog Breeds.
Now that you got a high-level picture of how the approach works. Let’s take a look at the step-by-step procedure for training and inferencing.
Loading Dataset
We would be using a dataset from Kaggle that you can find here(https://www.kaggle.com/c/dog-breed-identification). We will be Loading the data in a pandas dataframe named labels_dataframe and will convert each y label into a numerical value.
We have mapped every dog breed label with some numbers.
#Data Paths train_dir = '/kaggle/input/dog-breed-identification/train/'
labels_dataframe = pd.read_csv('/kaggle/input/dog-breed-identification/labels.csv')
dog_breeds = sorted(list(set(labels_dataframe['breed']))) n_classes = len(dog_breeds)
class_to_num = dict(zip(dog_breeds, range(n_classes)))
labels_dataframe['file_path'] = labels_dataframe['id'].apply(lambda x:train_dir+f"{x}.jpg")
labels_dataframe['breed'] = labels_dataframe.breed.map(class_to_num)

Now we will have to convert the breed column into y_train using to_categorical.
from keras.utils import to_categorical y_train = to_categorical(labels_dataframe.breed)
Extract Bottleneck Features in Stacked Pretrained Models
In this step, we will use the stacked_model that we have just designed for bottleneck feature extraction and these extracted features will become our X_train for our training. we are using batches so that we won’t have any OOM (Out of Memory) issues.
# for feature_extraction dataframe must have to contain file_path and breed columns
def feature_extractor(df):
img_size = (331,331,3)
data_size = len(df)
batch_size = 20
X = np.zeros([data_size,3072], dtype=np.uint8)
datagen = ImageDataGenerator() # here we dont need to do any image augementaion because we are prediction features
generator = datagen.flow_from_dataframe(df,
x_col = 'file_path', class_mode = None,
batch_size=20, shuffle = False,target_size = (img_size[:2]),color_mode = 'rgb')
i = 0
for input_batch in tqdm(generator):
input_batch = stacked_model.predict(input_batch)
X[i * batch_size : (i + 1) * batch_size] = input_batch
i += 1
if i * batch_size >= data_size:
break
return XX_train = feature_extractor(labels_dataframe)
here X_train (includes all features extracted by our pre-trained Model) is our new X_train which we will use for the final model.
Creating Predictor Model for Training
Now we will create a simple model that will take X_train (features extracted by stacked model) and y_train (categorical values) that will be the final predictor model.
import keraspredictor_model = keras.models.Sequential([
InputLayer(X.shape[1:]),
Dropout(0.7),
Dense(n_classes, activation='softmax')
])predictor_model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
from keras.callbacks import EarlyStopping,ModelCheckpoint, ReduceLROnPlateau
#Prepare call backs
EarlyStop_callback = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)
checkpoint = ModelCheckpoint('/kaggle/working/checkpoing',
monitor = 'val_loss',mode = 'min',save_best_only= True)
lr = ReduceLROnPlateau(monitor = 'val_loss',factor = 0.5,patience = 3,min_lr = 0.00001)
my_callback=[EarlyStop_callback,checkpoint]
this block of code will save the best epoch automatically ,
early-stopping and it will reduce learning rate if no further
improvement in training is seen.
Training the Model
Now we will train predictor_model on X_train and y_train and our X_test, y_test will be automatically taken by validation_split.
#Train simple DNN on extracted features.# here X is bottleneck feature extracted by using stacked pretrained model history_graph = predictor_model.fit(X_train , y_train,
batch_size=128,
epochs=60,
validation_split=0.1 ,
callbacks = my_callback)
use validation_split = 0.1, will split dataset into train (90%) and test (10%).
Plot the results
We will plot the history of our training and figure out our performance. here history_graph is the history object which we will use to plot the history over every epoch.
import matplotlib.pyplot as plt fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 12)) ax1.plot(history_graph.history['val_loss'],color = 'r',label = 'val_loss') ax1.set_xticks(np.arange(1, 60, 1)) ax1.set_yticks(np.arange(0, 1, 0.1)) ax1.legend(['loss','val_loss'],shadow = True) ax2.plot(history_graph.history['accuracy'],color = 'green',label = 'accuracy') ax2.plot(history_graph.history['val_accuracy'],color = 'red',label = 'val_accuracy') ax2.legend(['accuracy','val_accuracy'],shadow = True) # ax2.set_xticks(np.arange(1, 60, 1)) # ax2.set_yticks(np.arange(0, 60, 0.1)) plt.show() ax1.plot(history_graph.history['loss'],color = 'b',label = 'loss')
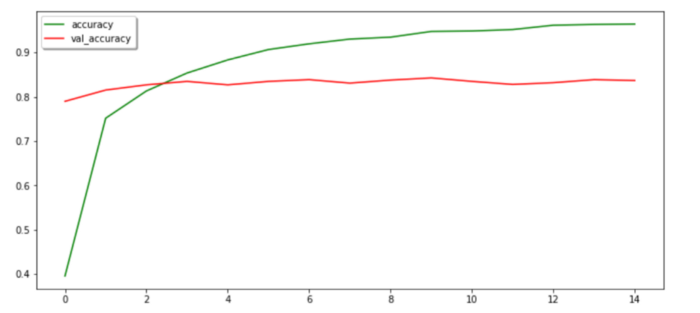
We have trained our model efficiently and got a validation accuracy of approx 85%. Well, we can improve it further we will talk about it at the end.
Save the Model
Finally, we will save the pre-trained model in order to use it for inference later.
dnn.save('/kaggle/working/dogbreed.h5')
stacked_model.save('/kaggle/working/feature_extractor.h5')
Getting the Inferences from the Model
To begin with, we will extract bottleneck features of test_images by stacked_model and then we will pass extracted features to predictor_model to get class values.
img = load_img(img_path, target_size=(331,331))
img = img_to_array(img)
img = np.expand_dims(img,axis = 0) # this is creating tensor(4Dimension)
extracted_features = stacked_model.predict(img)
y_pred = predictor_model.predict(extracted_features)
y_pred is a prediction array of shapes (1,120). y_pred is an array of having the probability of each class. now we need to find a class label that has the highest probability and then convert the class number to a class label using a
dictionary class_to_num that we have already defined.
def get_key(val):
for key, value in class_to_num.items():
if val == value:
return key
pred_codes = np.argmax(y_pred, axis = 1)predicted_dog_breed = get_key(pred_codes)

Source: Local
Conclusion
In this article, we built a dog breed classifier using stacked (densenet121, resnet50v2) and got a validation accuracy of over 85%. nevertheless, we can improve this accuracy furthermore ….
Improving Accuracy Further
- Try to stack other deep layered pre-trained models (VGG19, VGG16, etc.)
- Perform data augmentation before feature extraction
Now you know that using different pre-trained models you can create multiple other classifier models that work better in classifying the images. You can go ahead and create your own stacked model for your use case.
Thanks for reading this article do like if you have learned something new, feel free to comment See you next time !!! ❤️
Applied Machine Learning Engineer skilled in Computer Vision/Deep Learning Pipeline Development, creating machine learning models, retraining systems, and transforming data science prototypes to production-grade solutions. Consistently optimizes and improves real-time systems by evaluating strategies and testing real-world scenarios.




Hi, Thanks for it but are your sure about your codes? I think some parts are missing.