Logistic regression is a statistical model used to predict binary outcomes (yes/no, true/false). It is widely used in finance, marketing, healthcare, and social sciences. The model applies a logistic function to estimate the probability of an outcome based on predictor variables.
This article covers logistic regression in machine learning, including its types and key concepts.
This article was published as a part of the Data Science Blogathon
Table of contents
- What is Machine Learning?
- Types of Machine Learning
- What is Logistic Regression Model ?
- Why the Name Logistic Regression?
- Logit function to Sigmoid Function
- Requirements for Logistic Regression
- Decision Boundary – Logistic Regression
- Cost function – Linear Regression Vs Logistic Regression
- How to Reduce Cost Function? – Gradient Descent
- Regularization
- How Logistic Regression links with Neural Network?
- Hyperparameter Fine-tuning – Logistic Regression
- Python Implementation
- Advantages of Logistic Regression
- Disadvantages of Logistic Regression
- Application of Logistic Regression
- Frequently Asked Questions
What is Machine Learning?
Machine learning is like giving brains to computers. Instead of telling them exactly what to do, we let them learn from their experiences. They get better at tasks by learning from data.
Machine Learning algorithms can access data (categorical, numerical, image, video, or anything) and use it to learn for themselves without any explicit programming. But how does the Machine Learning technique work? just by observing the data (through instructions to observe the pattern and making decisions or predictions).
Types of Machine Learning
Machine learning comes in three flavors: supervised learning, unsupervised learning, and reinforcement learning. It’s like teaching a kid with clear instructions, leaving them to explore on their own, or guiding them through rewards and punishments.
Machine Learning algorithmic techniques can be broadly classified into three types,
- Supervised Machine Learning – Task Driven (Classification and Regression)
- Unsupervised Machine Learning – Data-Driven (Clustering)
- Reinforcement Machine Learning – Learning from mistakes (Rewards or Punishment)
Supervised Machine Learning
Algorithms in supervised learning are trained using labeled datasets, where the algorithm learns from each category of input. Once the training phase is complete, the algorithm is assessed on test data, which is a subset of the training set, and makes predictions accordingly. Supervised Machine Learning is classified into two types,
Regression
Regression procedures are applied when there is a relationship between the input variable and the output variable. This technique is commonly used to forecast continuous variables such as weather patterns, market trends, and other phenomena.
Classification
When the output variable is categorical, such as Yes-No, Male-Female, True-False, Normal-Abnormal, etc., classification methods are employed. These methods aim to classify input data into predefined categories or classes.
What is Logistic Regression Model ?
Logistic regression is a handy tool for picking between two choices. It’s like predicting if it’s going to rain or shine tomorrow based on today’s weather.
Logistic regression estimates the relationship between a dependent variable and one or more independent variables and predicts a categorical variable versus a continuous one. Here are a few things to know about logistic regression:
- Logistic regression is a Machine Learning method used for classification tasks.
- It is a predictive analytic technique based on the probability idea.
- The dependent variable in logistic regression is binary (coded as 1 or 0).
- The goal is to discover a link between characteristics and the likelihood of a specific outcome.
- Logistic regression uses a more sophisticated cost function called the “Sigmoid function” or “logistic function” instead of a linear function.
- The logistic regression hypothesis limits the cost function to a value between 0 and 1, making linear functions unsuitable for this task.
- Logistic regression finds applications in various fields such as finance, marketing, healthcare, and social sciences, where it is employed to model and predict binary outcomes.
Logistic Regression is considered a regression model also. This model creates a regression model to predict the likelihood that a given data entry belongs to the category labeled “1.” Logistic regression models the data using the sigmoid function, much as linear regression assumes that the data follows a linear distribution.
Why the Name Logistic Regression?
We call it logistic regression because of its special trick, the sigmoid function. Think of it as a secret formula that turns numbers into probabilities, helping us decide between two outcomes. Or, we can say ‘Logistic Regression’ since the technique behind it is quite similar to Linear Regression. The name “Logistic” originates from the Logit function, which plays a central role in this categorization approach.
Why Can’t we use Linear Regression Instead of Logistic Regression?
Before answering this question, we will explain from Linear Regression concept, from the scratch then only we can understand it better. Although logistic regression is a sibling of linear regression, it is a classification technique, despite its name. Using linear regression for categories is like trying to fit a square peg into a round hole. It might work, but it won’t give us accurate results like logistic regression does.
Mathematically, one can explain linear regression as follows:
- y = mx + c
- y – predicted value
- m – slope of the line
- x – input data
- c- Y-intercept or slope
We can forecast y values such as using these values. Now observe the below diagram for a better understanding,
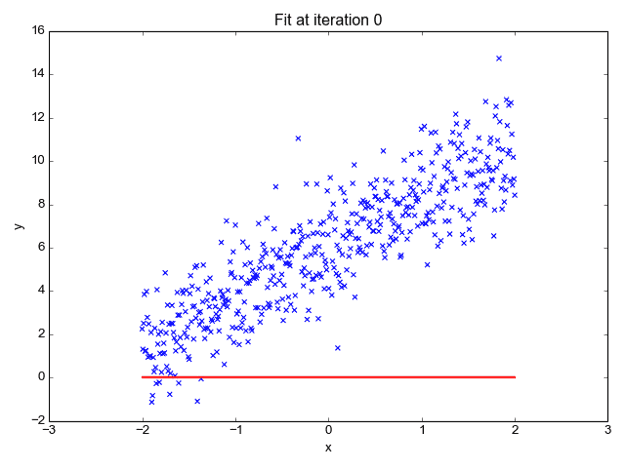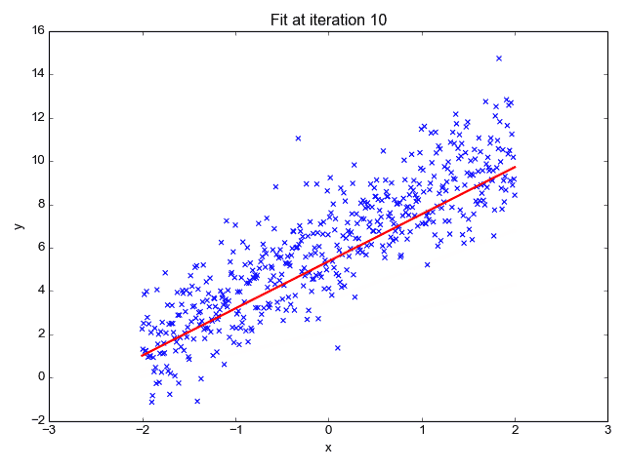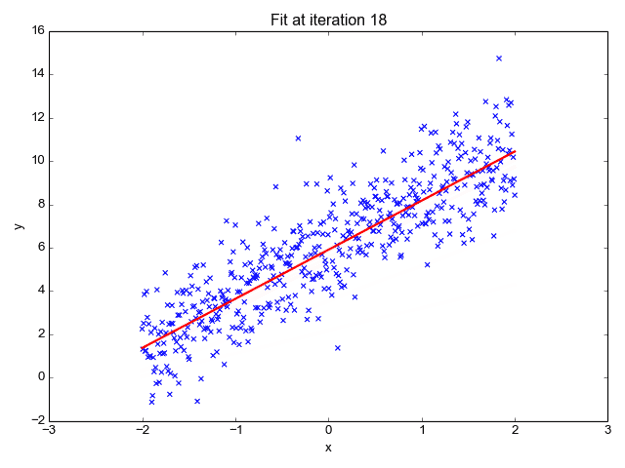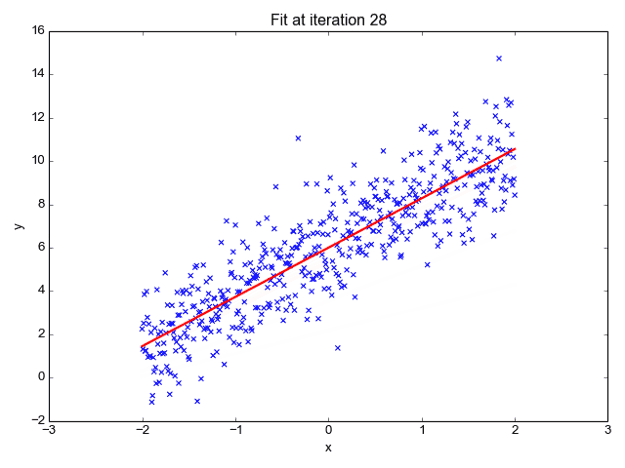
The x values are represented by the blue dots (the input data). We can now compute slope and y coordinate using the input data to ensure that our projected line (red line) covers most of the locations. We can now forecast any value of y given its x values using this line.
One thing to keep in mind about linear regression is that it only works with continuous data. If we want to include linear regression in our classification methods, we’ll have to adjust our algorithm a little more. First, we must choose a threshold so that if our projected value is less than the threshold, it belongs to class 1; otherwise, it belongs to class 2.
Now, if you’re thinking, “Oh, that’s simple, just create linear regression with a threshold, and hurray!, classification method,” there’s a catch. We must specify the threshold value manually, and calculating the threshold for huge datasets will be impossible. Furthermore, even if our anticipated values vary, the threshold value will remain the same. A logistic regression, on the other hand, yields a logistic curve with values confined to 0 and 1. In logistic regression, we generate the curve by using the natural logarithm of the target variable’s “odds” rather than the probability, as in linear regression. Additionally, the predictors do not need to be regularly distributed or have the same variance in each group.
And Now the Question?
Our beloved person, Andrew Ng, explained this famous title question. Let’s assume we have information about tumor size and malignancy. Because this is a classification issue, we can see that all the values will fall between 0 and 1. And, by fitting the best-found regression line and assuming a threshold of 0.5, we can do a very good job with the line.

We can select a point on the x-axis where all values to the left are considered negative, and all values to the right are regarded as positive.

But what if the data contains an outlier? Things would become shambles. For 0.5 thresholds, for example,

Even if we fit the best-found regression line, we won’t be able to determine any point where we can distinguish classes. It will insert some instances from the positive class into the negative class. The green dotted line (Decision Boundary) separates malignant and benign tumors, however, it should have been a yellow line that clearly separates the positive and negative cases. As a result, even a single outlier can throw the linear regression estimates off. And it’s here that logistic regression comes into play.
Logit function to Sigmoid Function
Moving from the logit function to the sigmoid function is like turning raw data into something we can actually use, sort of like turning a block of wood into a finely crafted sculpture.
Logistic Regression can be expressed as,
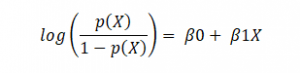
where p(x)/(1-p(x)) is termed odds, and the left-hand side is called the logit or log-odds function. The odds are the ratio of the chances of success to the chances of failure. As a result, in Logistic Regression, a linear combination of inputs is translated to log(odds), with an output of 1.
The following is the inverse of the aforementioned function
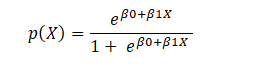
This is the Sigmoid function, which produces an S-shaped curve. It always returns a probability value between 0 and 1. The Sigmoid function is used to convert expected values to probabilities. The function converts any real number into a number between 0 and 1. We utilize sigmoid to translate predictions to probabilities in machine learning.
The mathematically sigmoid function can be,
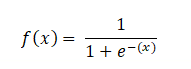

Types of Logistic Regression
Just like there are different types of pizza, there are different types of logistic regression: binary, multinomial, and ordinal. Each one serves a different purpose.
- Binary Logistic Regression – two or binary outcomes like yes or no
- Multinomial Logistic Regression – three or more outcomes like first, second, and third class or no class degree
- Ordinal Logistic Regression – three or more like multinomial logistic regression but here with the order like customer rating in the supermarket from 1 to 5
Requirements for Logistic Regression
To use logistic regression, you need clean data, no big surprises between data points, and a straight line that shows the relationship between variables.
This model can work for all the datasets, but still, if you need good performance, then there will be some assumptions to consider,
- The dependant variable in binary logistic regression must be binary.
- Only the variables that are relevant should be included.
- The independent variables must be unrelated to one another. That is, there should be minimal or no multicollinearity in the model.
- The log chances are proportional to the independent variables.
- Large sample sizes are required for logistic regression.
Decision Boundary – Logistic Regression
The decision boundary in logistic regression is like a fence that separates the cats from the dogs. It’s where we say, “This side is for cats, and that side is for dogs.”
We can establish a threshold to predict the class to which a given data point belongs. The estimated probability obtained is then classified into classes based on this threshold.
If the predicted value is less than 0.5, categorize the particular student as a pass; otherwise, label it as a fail. There are two types of decision boundaries: linear and non-linear. To provide a complicated decision boundary, the polynomial order can be raised.
Why can’t we use the cost function used for linearity for logistic regression?
The cost function for linear regression is mean squared error. If we use it for logistic regression, the parameter function will become non-convex. Only if the function is convex will gradient descent lead to a global minimum.
Cost function – Linear Regression Vs Logistic Regression
In linear regression, we measure how far our guesses are from the real thing. In logistic regression, we measure how close our guesses are to the probabilities we want.
Linear regression employs the Least Squared Error as the loss function, which results in a convex network, which we can then optimize by identifying the vertex as the global minimum. For logistic regression, however, it is no longer a possibility. Also, modifying the hypothesis results in a non-convex graph with local minimums when calculating Least Squared Error using the sigmoid function on raw model output.
What is cost function? Cost functions are used in machine learning to estimate how poorly models perform. Simply put, a cost function is a measure of how inaccurate the model is in estimating the connection between X and y. This is usually stated as a difference or separation between the expected and actual values. A machine learning model’s goal is to discover parameters, weights, or a structure that minimizes the cost function.
A convex function indicates there will be no intersection between any two points on the curve, but a non-convex function will have at least one intersection. In terms of cost functions, a convex type always guarantees a global minimum, whereas a non-convex type only guarantees local minima.

How to Reduce Cost Function? – Gradient Descent
Gradient descent is like taking small steps down a hill to find the shortest path. It helps us tweak our model to make it as accurate as possible.
The challenge now is: how can we lower the cost value? Gradient Descent can be used to accomplish this. Gradient descent’s main objective is to reduce the cost value.
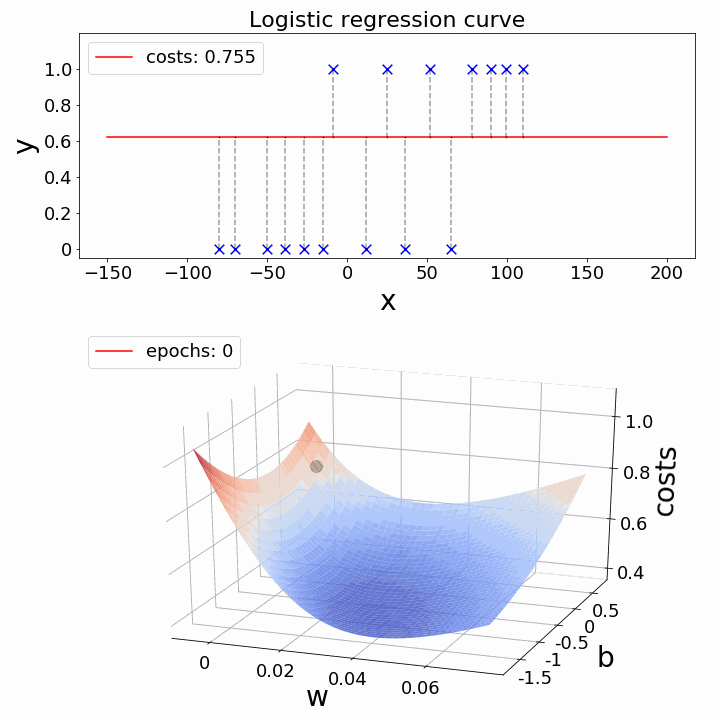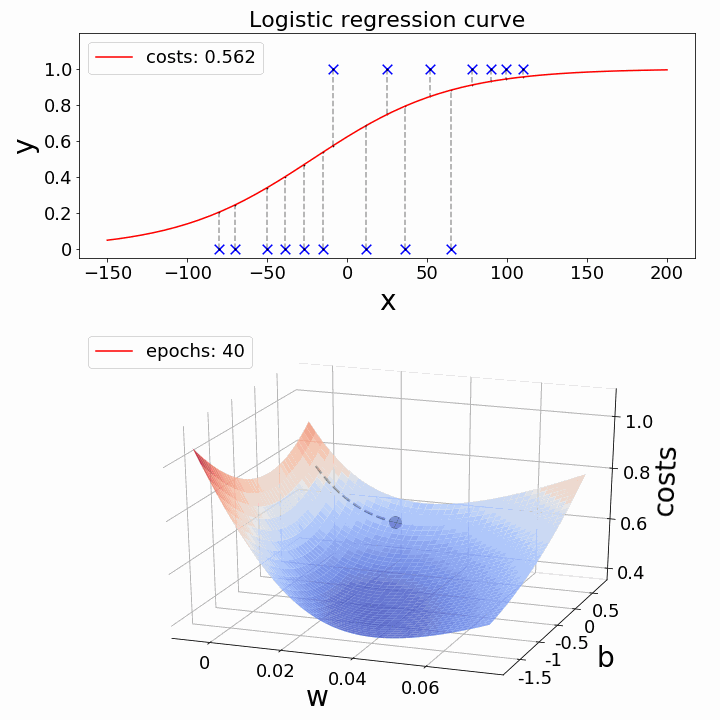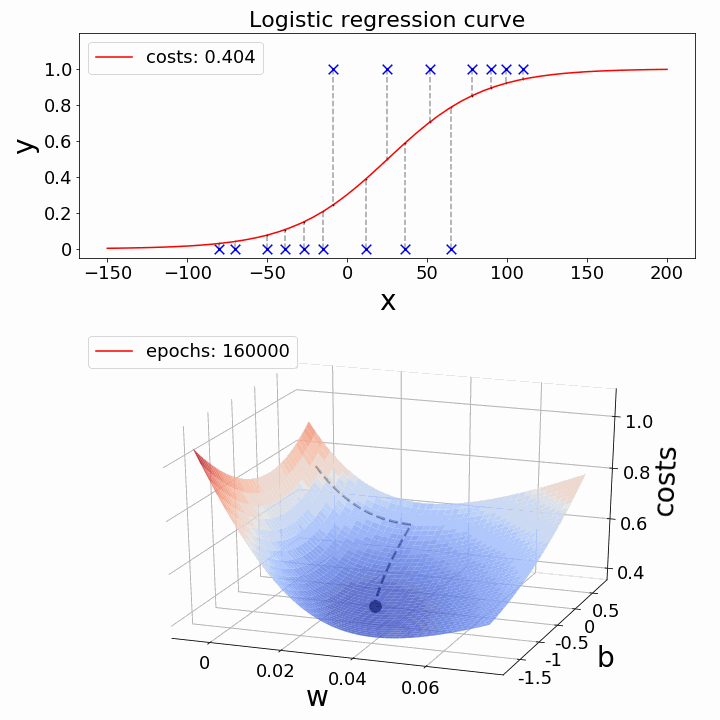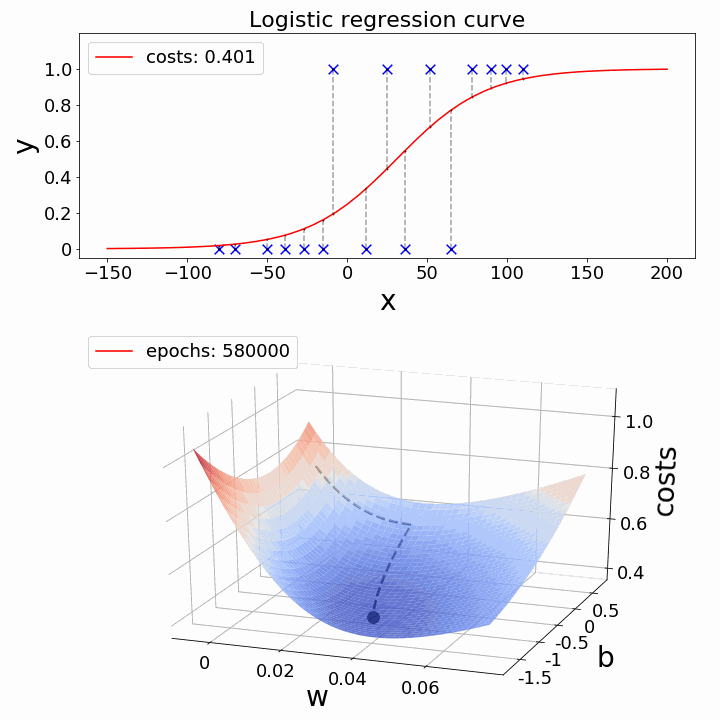
Regularization
Regularization is like adding guardrails to a race track. It stops our model from going off track and overfitting, keeping it in check with below giving points :
- Regularization helps reduce the cost function to match parameters to training data.
- The two most common types of regularization are:
- L1 Regularization (Lasso)
- L2 Regularization (Ridge)
- Instead of just maximizing the cost function, regularization limits the size of coefficients to prevent overfitting.
- L1 and L2 have different approaches to controlling coefficient values:
- L1 (Lasso):
- Performs feature selection by setting some coefficients to 0.
- Helps in reducing multi-collinearity.
- L2 (Ridge):
- Penalizes large coefficients but does not set any to 0.
- L1 (Lasso):
- A regularization parameter (λ) controls the weight of the constraint:
- Ensures coefficients are not penalized too much, which could lead to underfitting.
- L1 and L2 behave differently because of the ‘squared’ and ‘absolute’ values in their calculations.
- The impact of λ on regularized and original fit terms is an interesting concept to explore further.
- Below are the steps to convert an original cost function into a regularized cost function.

How Logistic Regression links with Neural Network?
Logistic regression and neural networks are like cousins. They share some similarities, but neural networks are like the big brother with more tricks up its sleeve.
We all know that Neural Networks are the foundation for Deep Learning. The best part is that Logistic Regression is intimately linked to Neural networks. Each neuron in the network may be thought of as a Logistic Regression; it contains input, weights, and bias, and you conduct a dot product on all of that before applying any non-linear function. Furthermore, a neural network’s last layer is a basic linear model (most of the time). That can be understood by visualization as shown below,

Take a deeper look at the “output layer,” and you’ll notice that it’s a basic linear (or logistic) regression: we have the input (hidden layer 2), the weights, a dot product, and finally a non-linear function, depends on the task. A helpful approach to thinking about neural networks is to divide them into two parts: representation and classification/regression. The first section (on the left) aims to develop a decent data representation that will aid the second section (on the right) is doing a linear classification/regression.

Hyperparameter Fine-tuning – Logistic Regression
Hyperparameter fine-tuning is like adjusting the knobs on a radio until you find the perfect station. It helps us optimize our model for peak performance.
There are no essential hyperparameters to adjust in logistic regression. Even though it has many parameters, the following three parameters might be helpful in fine-tuning for some better results,
Regularization (penalty) might be beneficial at times.
Penalty – {‘l1’, ‘l2’, ‘elasticnet’, ‘none’}, default=’l2’
The penalty strength is controlled by the C parameter, which might be useful.
C – float, default=1.0
With different solvers, you might sometimes observe useful variations in performance or convergence.
Solver – {‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’}, default=’lbfgs’
Note: The algorithm to use is determined by the penalty: Solver-supported penalties:
- ‘newton-cg’ – [‘l2’, ‘none’]
- ‘lbfgs’ – [‘l2’, ‘none’]
- ‘liblinear’ – [‘l1’, ‘l2’]
- ‘sag’ – [‘l2’, ‘none’]
- ‘saga’ – [‘elasticnet’, ‘l1’, ‘l2’, ‘none’]
Python Implementation
Python makes implementing logistic regression a breeze. With libraries like scikit-learn and TensorFlow, we can crunch data and build models without breaking a sweat.
Whenever we start writing the program, always our first step is to start with importing libraries,
mport numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
dataset = pd.read_csv('data.csv')
print(dataset.head())Next to importing libraries, it’s our data to import, either from local disk or from url link
Before getting into modeling, we need to understand the statistical importance for better understanding,
dataset.info()
dataset.shape
dataset.describe().T
print(str('Any missing data or NaN in the dataset:'),dataset.isnull().values.any())If you understand the correlation between the features, it will be easy to process, like adding for modeling or removing
corr_var=dataset.corr()
print(corr_var)
plt.figure(figsize=(10,7.5))
sns.heatmap(corr_var, annot=True, cmap='BuPu')We need to separate dependent and independent features before modeling,
X = dataset.iloc[:,:-1].values
y = dataset.iloc[:,-1].valueswe need to split to the standard format (70:30 or 80:20) for training and testing of data during the modeling process for better accuracy.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split (X, y, test_size=0.2, random_state=0)
print('Total no. of samples: Training and Testing dataset separately!')
print('X_train:', np.shape(X_train))
print('y_train:', np.shape(y_train))
print('X_test:', np.shape(X_test))
print('y_test:', np.shape(y_test))As we have different features, each has different scaling or range, we need to do scaling for better accuracy during training and for new dataset
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)Importing Logistic Regression from scikit learn
from sklearn.linear_model import LogisticRegression
classifier7 = LogisticRegression()
classifier7.fit(X_train,y_train)Predicting the end result from the test data set
y_pred7 = classifier7.predict(X_test)
print(np.concatenate((y_pred7.reshape(len(y_pred7),1), y_test.reshape(len(y_test),1)),1))finally, we need to evaluate it through classification metrics like confusion matrix, accuracy, and roc-auc score,
from sklearn.metrics import confusion_matrix, accuracy_score, roc_auc_score
cm7 = confusion_matrix(y_test, y_pred7)
print(cm7)Visualizing confusion matrix for a better view
from mlxtend.plotting import plot_confusion_matrix
fig, ax = plot_confusion_matrix(conf_mat=cm7, figsize=(6, 6), cmap=plt.cm.Greens)
plt.xlabel('Predictions', fontsize=18)
plt.ylabel('Actuals', fontsize=18)
plt.title('Confusion Matrix', fontsize=18)
plt.show()Accuracy of our model
logreg=accuracy_score(y_test,y_pred7)
logregThen finally, AUC-ROC score value, closer to 1 makes the system more accurate
roc_auc_score(y_test, y_pred7)Overall metrics report of the logistic regression by Precision, Recall, F1 Score makes more understanding by how detailed our model predicts the data
import sklearn.metrics as metrics
print(metrics.classification_report(y_test, y_pred7))

Hyperparameter makes our model more fine-tune the parameters and also we can manually fine-tune our parameters for robust model and can see the difference in importance of using parameters
from sklearn.model_selection import GridSearchCV
parameters_lr = [{'penalty':['l1','l2'],'C': [0.001, 0.01, 0.1, 1, 10, 100, 1000]}]
grid_search_lr = GridSearchCV(estimator = classifier7,
param_grid = parameters_lr,
scoring = 'accuracy',
cv = 10,
n_jobs = -1)
grid_search_lr.fit(X_train, y_train)
best_accuracy_lr = grid_search_lr.best_score_
best_paramaeter_lr = grid_search_lr.best_params_
print("Best Accuracy of LR: {:.2f} %".format(best_accuracy_lr.mean()*100))
print("Best Parameter of LR:", best_paramaeter_lr)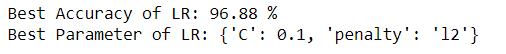
Advantages of Logistic Regression
Logistic regression has its perks, like being easy to understand, but it’s not without its flaws, such as struggling with complex relationships in data.
- Overfitting is less likely with logistic regression, although it can happen in high-dimensional datasets. In these circumstances, regularization (L1 and L2) techniques may be used to minimize over-fitting.
- It works well when the dataset is linearly separable and has good accuracy for many basic data sets.
- It is more straightforward to apply, understand, and train.
- The inferences regarding the relevance of each characteristic are based on the anticipated parameters (trained weights). The association’s orientation, positive or negative, is also specified.As a result, logistic regression can be utilized to determine the relationship between characteristics. Unlike decision trees or support vector machines, this technique permits models to be easily adjusted to accommodate new data. Stochastic gradient descent can be employed for data updating.
- It is less prone to over-fitting in a low-dimensional dataset with enough training instances.
- When the dataset includes linearly separable characteristics, Logistic Regression shows to be highly efficient.
- It has a strong resemblance to neural networks. A neural network representation may be thought of as a collection of small logistic regression classifiers stacked together.
- The training time of the logistic regression method is considerably smaller than that of most sophisticated algorithms, such as an Artificial Neural Network, due to its simple probabilistic interpretation.
- Multinomial Logistic Regression is the name given to an approach that may easily be expanded to multi-class classification using a softmax classifier.
Disadvantages of Logistic Regression
- Logistic Regression is not advisable when the number of observations is fewer than the number of features, as this can lead to overfitting.
- Because it creates linear boundaries, we won’t obtain better results when dealing with complex or non-linear data.
- It’s only good for predicting discrete functions. As a consequence, the Logistic Regression model is constrained to having a dependent variable that is restricted to a discrete numerical set.
- Logistic regression requires that there is little to no multicollinearity between independent variables.
- Logistic regression needs a big dataset and enough training samples to identify all of the categories.
- Because this method is sensitive to outliers, the presence of data values in the dataset that differs from the anticipated range may cause erroneous results.
- Utilizing only significant and relevant features is crucial in constructing a model. Otherwise, the model’s probabilistic predictions might be inaccurate, leading to a decline in its predictive value.
- Complex connections are difficult to represent with logistic regression. More powerful and sophisticated algorithms, such as Neural Networks, often outperform this technique readily.
- Because logistic regression has a linear decision surface, it cannot address nonlinear issues. In real-world settings, linearly separable data is uncommon. Consequently, transforming non-linear features becomes necessary, often achieved by augmenting the feature space to enable linear separation in higher dimensions.
- Based on independent variables, a statistical analysis model seeks to predict accurate probability outcomes. On high-dimensional datasets, this may cause the model to be over-fit on the training set, overstating the accuracy of predictions on the training set, and so preventing the model from accurately predicting outcomes on the test set. This commonly occurs when training the model with a small amount of training data and numerous features. Exploring regularization strategies on high-dimensional datasets becomes essential to mitigate overfitting, although this complexity adds to the model. The model may be under-fit on the training data if the regularization parameters are too high.
Application of Logistic Regression
Logistic regression finds its way into many areas, from healthcare to finance. It helps with things like predicting diseases or figuring out which customers might leave
All use cases where data must be categorized into multiple groups are covered by Logistic Regression. Consider the following illustration:
- Fraud detection in Credit card
- Email spam or ham
- Sentiment Analysis in Twitter analysis
- Image segmentation, recognition, and classification – X-rays, Scans
- Object detection through video
- Handwriting recognition
- Disease prediction – Diabetes, Cancer, Parkinson etc..
Conclusion
The logistic regression model empowers binary classification tasks. It finds extensive application across diverse fields like finance, marketing, healthcare, and social sciences for modeling and forecasting binary outcomes. Our Blackbelt program is an excellent resource for individuals learning more about machine learning and advanced analytics. The program covers various topics, including data preparation, feature engineering, model selection, and evaluation techniques. Sign-up today!
Hope you like the article and get understanding about the logistics regression and logistic regression in machine learning. This is a proper guide where you can understand this.
Frequently Asked Questions
Q1.What is the main difference between linear regression and logistic regression?
Linear regression predicts continuous values (like house prices) with a straight line, while logistic regression predicts probabilities (like spam/not spam) using an S-shaped curve.
Q2.What is the formula for logistic regression?
logistic regression uses a linear combination of features and weights (Σ(wi * xi) + b) passed through a sigmoid function (σ) to predict the probability (between 0 and 1) of an observation belonging to a specific class.
Premanand S is a dedicated academic with over a decade of research experience specializing in Bio-signal Processing, Machine Learning, and Deep Learning. He earned his B.Tech in 2009 from Amrita Vishwa Vidyapeetham, Bangalore, and completed his M.E. in 2011 from Rajalakshmi Engineering College, Chennai, where his thesis focused on Deep Learning for ECG Signal Processing.
Currently pursuing his Ph.D. at VIT-Chennai, his research, titled "Deep Learning Approaches for Enhanced ECG Signal Processing and Arrhythmia Classification," aims to leverage cutting-edge deep learning techniques to improve the accuracy and efficiency of ECG signal analysis, contributing significantly to advancements in cardiac health monitoring.
A recipient of the prestigious TCS-RSP (Research Scholarship) in 2014, Cycle 9, Premanand has established himself as a recognized figure in the academic community. He has been invited to deliver talks on Data Science, Machine Learning, and Deep Learning at prominent institutions across India, sharing his expertise and insights with researchers and students alike.
As an Assistant Professor at VIT-Chennai, he continues to mentor and inspire the next generation of researchers while pushing the boundaries of knowledge in his field.







This blog post is really informative. I learned a lot from it.