This article was published as a part of the Data Science Blogathon.
Introduction
Data is defined as information that has been organized in a meaningful way. We can use it to represent facts, figures, and other information that we can use to make decisions. Data collection is critical for businesses to make informed decisions, understand customers’ wants and needs, and track progress. When done correctly, data can provide insights that help companies to improve their products, services, and bottom line.
There are many different types of data businesses can collect, but some of the most important include the following:
1. Demographic data: This includes information about the age, gender, income, location, and other characteristics of your target market. This data can help you understand your customers and what they want. It includes information about the age, gender, income, location, and other characteristics of your target market. This data can help you understand your customers and what they want.
2. Psychographic Data delves into your target market’s lifestyle, values, and attitude. This data can help you understand what motivates your customers and how to reach them best.
What is Data Mining?
Data mining is the process of extracting valuable information from large data sets. It is a powerful tool that we can use to identify trends, patterns, and relationships buried in data.
We can use data mining to solve various business problems, such as identifying customer buying patterns, detecting fraud, and improving marketing campaigns.
When used correctly, data mining can be a powerful tool that provides insights that would otherwise be hidden. However, data mining can also be misused, resulting in privacy concerns and ethical issues.

In the past decade, data lakes and data warehouses have become increasingly popular tools for data analytics. While they are both used to store and analyze data, some key differences between the two should be considered when choosing which one to use for your data analytics needs. Let’s discuss Data Lake and Data Warehouse in detail in the particular blog.
Let’s get started 😉
What is Data Lake?
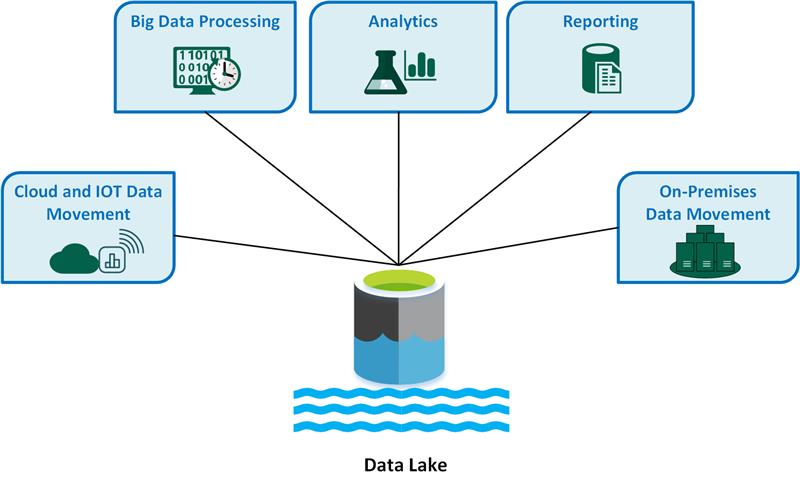
Most organizations have data spread across many different systems and databases. A data lake is a repository that can store all of this data in its rawest form, making it easier to access and analyze.
A data lake is usually a single store of data we can use to answer multiple business questions. It contrasts with a data warehouse designed to support a single business function. Data lakes are often used to support data science and analytics initiatives, making accessing and preparing data for analysis easier. We can build data lakes on top of various storage platforms, including object stores, HDFS, and cloud storage. We can also use them to ingest data from multiple sources, including streaming data, social media, and log files.
When designed and used correctly, data lakes can be a powerful tool for organizations that want to use their data better. However, data lakes can also be a source of chaos if they are not well managed.
Benefits:
There are many benefits of data lakes, including:
1. Increased Agility and Flexibility: Organizations can more easily and quickly respond to new business opportunities and changing market conditions with a data lake.
2. Improved Scalability: Data lakes can scale more efficiently than traditional data warehouses since they don’t require the same upfront planning and investment level.
3. Reduced costs: Data lakes can be more cost-effective than data warehouses since they don’t require as much expensive hardware and software.
4. Better Decision Making: With a data lake, organizations can make better decisions by having access to more data and being able to more easily and quickly analyze it.
5. Improved Security: Data lakes can offer better protection than data warehouses since they can be designed to include security controls from the outset.
6. Greater Compliance: Data lakes can help organizations meet compliance requirements by providing a centralized repository for all data.
Architecture:
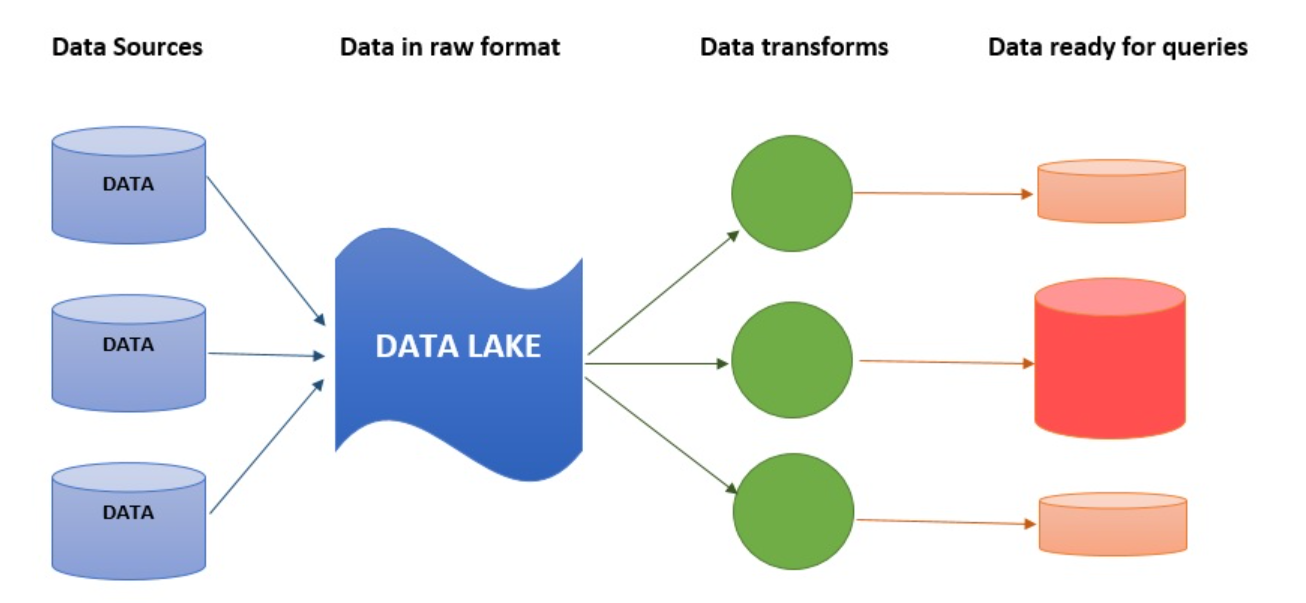
Data lakes are a new and popular way to store and analyze data. They often store data from multiple sources in a single place for easy access and analysis. Data lakes are usually built on a distributed file system, such as Hadoop, that can scale to meet the needs of big data applications. The data in a data lake can be structured, semi-structured, or unstructured. Data lakes are often used for data warehousing, mining, and machine learning applications.
Data lakes are usually composed of three main components:
1. Data Store: This is where all the data is stored in a raw and unstructured format.
2. Data Processing Engine: This is used to process and analyze the data.
3. Data Visualization Tool: This is used to visualize the data and help businesses make better decisions.
Limitations:
There are a few potential limitations of data lakes that should be considered before implementing one:
1. Data lakes can be complex and challenging to set up and manage. Without the right expertise and tools, a data lake can quickly become a messy and unorganized data swamp.
2. Data lakes can be pretty expensive to set up and maintain. Depending on the size and scale of the data lake, costs can quickly add up.
3. Data lakes can potentially lead to data silos if not appropriately managed. If data is not adequately organized and governed, it can be challenging to find and use later information.
4. Data lakes can be challenging to secure. Since data lakes often store sensitive data, it is essential to have proper security measures in place to protect the data.
5. Data lakes can be challenging to scale. As data lakes grow, it cannot be easy to keep track of all the data and ensure that it is properly organized.
What is Data Warehouse?
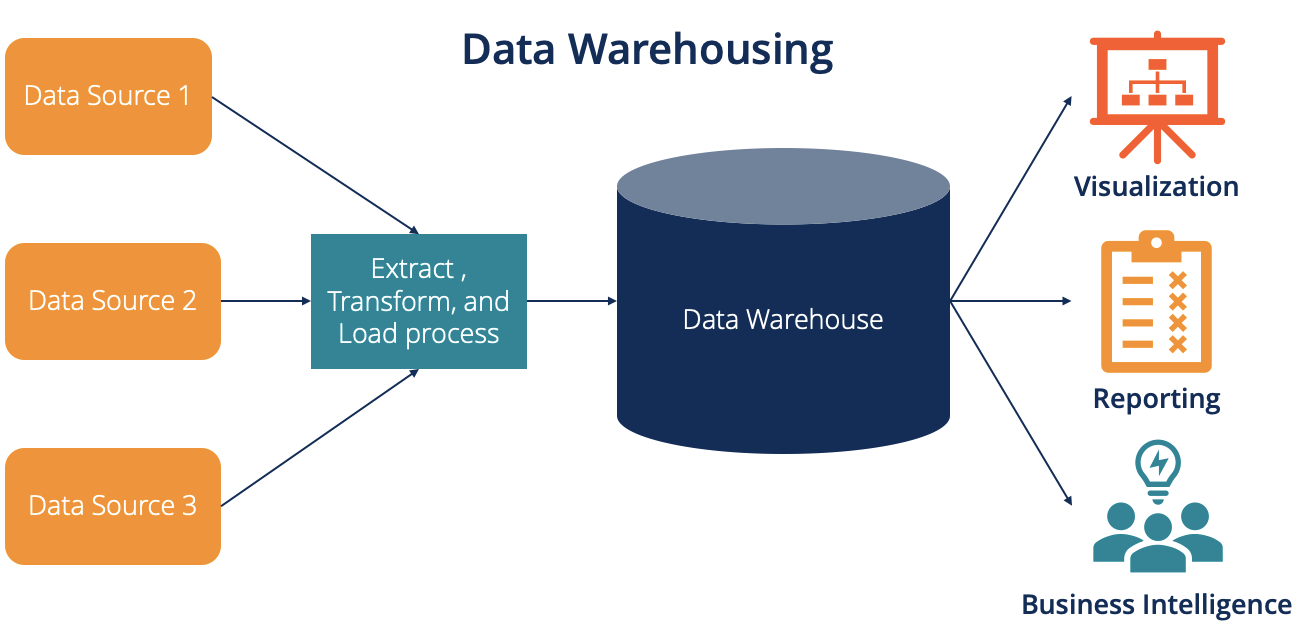
A data warehouse is a system that consolidates data from multiple sources into a single central repository. Data warehouses support business intelligence (BI) initiatives and enable organizations to make better decisions by providing timely, accurate data.
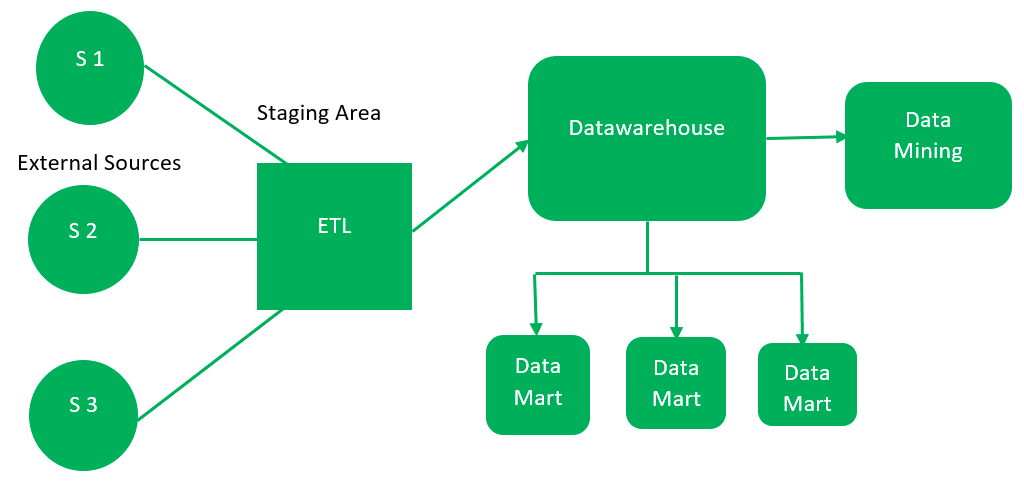
ETL stands for Extract, Transform, and Load. ETL is a process that extracts data from one or more sources, transforms it to meet the requirements of the data warehouse, and then loads it into the data warehouse. Data warehouses and ETL are essential components of business intelligence initiatives. By consolidating data from multiple sources and transforming it to meet the requirements of the data warehouse, businesses can gain insights into their operations and make better decisions.
Benefits:
Data warehouses offer several advantages over other data storage systems. They are designed to support data analysis and decision-making and are optimized for querying and reporting. Data warehouses also provide a central location for data that all users in an organization can access.
Data warehouses are designed to facilitate data analysis. They are typically arranged in a star schema, which organizes data into a series of tables connected by relationships. This schema makes it easy to write queries that return data from multiple tables. Data warehouses also typically include summary tables that contain aggregated data, which makes it easier to answer queries that require aggregate calculations.
Data warehouses are also optimized for reporting. Reporting tools can connect to data warehouses and run queries to generate reports. Business intelligence tools can also access data warehouses, allowing users to visualize data and spot trends.
Architecture:
The data warehouse architecture is a layered approach that allows for flexibility and scalability, and it typically includes the following components:
1. Data Sources: This is where data is extracted from operational systems and other external sources.
2. Data Transformation: Data warehouses typically transform the data to make it consistent and easy to use.
3. Data Cleansing: Data warehouses typically undergo extensive purification to ensure that the data is accurate and complete.
4. Data Staging Area: This is a temporary holding area for data extracted from the data sources.
5. Data Warehouse: This is the principal repository for all the data in the system.
6. Data Marts: This data warehouse subset is used to support specific decision-making needs.
7. Data Mining is analyzing data to look for patterns and trends.
Limitations:
There are a few limitations of data warehouses that are worth mentioning:
1. Data warehouses can be pretty expensive to set up and maintain. It is due to the need for specialized hardware and software, as well as the need for skilled personnel to manage and operate the system.
2. Data warehouses can be challenging to scale, mainly based on traditional relational database technology.
3. Data warehouses can be slow to query and update, impacting the system’s usability for some users.
Conclusion- Difference Between Data Lake and Data Warehouse
There has been a lot of debate lately about the differences between data lakes and data warehouses. Here is a quick rundown of the key differences:
Data lakes are designed to store all data, regardless of structure or format. It makes them ideal for storing unstructured data such as social media, log files, and sensor data. On the other hand, data warehouses are designed to store structured data that has been cleaned and formatted for easy analysis.
Data lakes are usually cheaper to build and maintain than data warehouses since they require less infrastructure and fewer resources. Data warehouses require more resources since they need to be able to handle complex queries and analyses.
Data lakes can be used for real-time analytics since all data is stored in one place. Data warehouses can also be used for real-time analytics, but this requires Extract, Transform, Load (ETL) processes to be in place to ensure data is cleansed and formatted correctly.
This debate on comparing them will continue very long, as both have their benefits and limitations. But I hope you must understand the fundamental difference between them and can differentiate when to use what. It is all for today. I will write more future articles on data storage and cloud computing, as these topics are in scorching demand nowadays.
Key takeaways of this article:
1. Firstly, we have discussed what data is and how this data can be extracted using data mining.
2. After that, we discussed data storage methods like Data Lake and Data Mining. In this section, we have discussed their benefits, basic architecture, and limitations.
3. Finally, we have concluded the article by identifying their fundamental differences.
It is all for today. I hope you have enjoyed the article. If you have any doubts or suggestions, feel free to comment below. Or you can also connect with me on LinkedIn. I will be delighted to get associated with you.
Do check my other articles also.
Thanks for reading, 😊
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am currently pursuing my Bachelor of Technology (B.Tech.) in Electrical Engineering and Engineering from the Indian Institute of Technology Jodhpur(IITJ). I am very enthusiastic about Machine learning, and Software Development. Feel free to connect with me on Linkedin.






