Introduction
Amazon Redshift is a fully managed, petabyte-scale data warehousing Amazon Web Services (AWS). It allows users to easily set up, operate, and scale a data warehouse in the cloud. Redshift uses columnar storage techniques to store data efficiently and supports data warehousing workloads intelligence, reporting, and analytics. It allows users to perform complex queries on large datasets in a matter of seconds, making for data warehousing and business intelligence applications. Redshift is integrated with other AWS services, EMR, and Kinesis, with its compliance features to ensure data is protected. Here, in this article, we will examine the top 6 frequently asked yet crucial Amazon Redshift Interview questions to help you bag that dream job.

Learning Objectives:
1. We will cover an overview of Amazon Redshift and its importance in data warehousing
2. Then, we will explain Redshift architecture, scalability, performance, pricing, and ease of use data loading and unloading in Redshift: COPY and UNLOAD command.
3. Further, you will get to know about the scaling of Redshift by adding or removing nodes.
4. Then, we will implement security and access control in Redshift: using AWS Identity and Access Management (IAM) and AWS Resource Access Manager (RAM).
5. Finally, we will compare Redshift with other data warehousing solutions like BigQuery, including their architecture, scalability, performance, pricing, and ease of use.
This article was published as a part of the Data Science Blogathon.
Table of Contents
- Introduction to Amazon Redshift Interview Questions
- Learning Objectives
- What is the Importance & Need of Amazon Redshift?
- How do you handle data replication and backups in Redshift?
- How do you implement security and access control in Redshift?
- How do you optimize query performance in Redshift?
- How do you handle data retention and data archiving in Redshift?
- Explain the differences between Redshift and other data warehousing solutions like BigQuery?
- Conclusion
Top 6 Amazon Redshift Interview Questions
Q1. What is the Importance and Need of Amazon Redshift?
Amazon Redshift is important for several reasons:
- Scalability: Redshift allows users to easily scale their data warehouse up or down to meet their business needs. This means the amount of data grows. Redshift can handle it without requiring time.
- Cost-effectiveness: Redshift is a fully managed service, which means that AWS handles all of the underlying infrastructure and maintenance. This can be more cost-effective than managing a data warehouse on-premises or using a cloud-based solution.
- Performance: Redshift uses columnar storage techniques to store data efficiently, which allows it to perform complex queries on large datasets in a matter of seconds. This makes for data warehousing and business intelligence applications where fast query performance is critical.
- Integration: Redshift can be easily integrated with other AWS services, EMR, and Kinesis, which allows users to easily access and analyze their data in the context of other data sources.
- Security: Redshift and compliance feature to ensure data is protected. This includes encryption at and compliance standards 2, PCI DSS, and HIPAA.
The need for Amazon Redshift comes from the growing amount of data generated by businesses. This data is often stored in various systems, making it difficult to access, analyze, and gain insights. Data warehousing services like Redshift provide a way to consolidate and organize large amounts of data in a single place, making it actionable. More companies are moving their data and workloads to the cloud. Redshift provides a way to leverage the scalability and cost-effectiveness of the cloud for data warehousing and business intelligence.
Q2. How do you Handle Data Replication and Backups in Redshift?
Handling data replication and backups in Amazon Redshift involves several steps:
Snapshots: Redshift provides a built-in data backup feature called snapshots. Snapshots are point-in-time backups that we can use to restore. You can schedule regular snapshots and retain them for days.
- Copy: You can use the “COPY” command to copy data from one table to another. This can be useful for creating backups of your data or for replicating data.
- Replication: Redshift supports multi-AZ deployments, providing automatic failover for high availability and data replication. This allows you to create a read replica of a different backup and disaster recovery.
- Encryption: Redshift supports the encryption of data at rest. This can be useful for protecting data during a data breach or other security incident.
It’s important to remember that data replication and backups are ongoing processes. Regularly schedule and test snapshots and replication to ensure that they are working properly and that you can restore your data failure or data loss.
Q3. How do you Implement Security and Access Control in Redshift?
Implementing security and access control in Amazon Redshift involves several steps:
Create IAM roles: You can use AWS Identity and Access Management (IAM) to create roles that control access. We can assign these roles to users, groups, or applications that need access.
Control network access: You can to your creating a security group. A security group virtual firewall that controls the traffic.
Create IAM roles: You can use AWS Identity and Access Management (IAM) to create roles that control access. We can assign these roles to users, groups, or applications that need access.
Control network access: You can to your creating a security group. A security group virtual firewall that controls the traffic.
- Use VPC: Redshift is integrated with Amazon Virtual Private Cloud (VPC) to place virtual control access to its control lists (ACLs) and security groups.
- Use security best practices: Redshift follows AWS security best practices, including protocols, regular software updates, and monitoring for security events.
- Control access to data: You can use Redshift’s built-in row-level security features to control access to data based on user roles and predefined conditions. This feature allows you to limit access to certain rows in a table based on specific conditions.
- Use multi-factor authentication: Multi-factor authentication (MFA) provide security by requiring users to provide authentication, fingerprint, or security token, in addition to their password.
Q4. How do you Optimize Query Performance in Redshift?

Optimizing query performance in Amazon Redshift involves several steps:
- Sort keys: Redshift uses a columnar storage model and stores data on a disk. Sort keys define the data and speed up query performance by reducing the amount of data that needs to be read.
- Distribution Styles: Redshift uses distribution styles to define how data the nodes are in. We can use this to optimize query performance by distributing data in a way that reduces data movement.
- Compression: Redshift uses compression to reduce the amount of disk storage data. Compression is used to speed up query performance by reducing the amount of data that needs to be read.
- Vacuum: Redshift uses a vacuum process to reclaim space from deleted or updated rows that have been added or updated. Running improves query performance by keeping the data.
- Analyze: Redshift uses the Analyze process to update statistics about data distribution in tables and make better query optimization decisions. It’s important to keep the statistics up-to-date.
- Indexing: You can use indexes in Redshift to speed up query performance by reducing the amount of data that needs to be scanned.
- Query Optimization: You can use the Redshift Query Optimizer to analyze your queries and make recommendations for improving performance.
- Performance Monitoring: You can use Redshift’s built-in performance monitoring tools, Performance Insights, and the system tables to identify and troubleshoot performance issues. It’s important to remember that query performance optimization is an ongoing process. Regularly monitor your queries and performance to keep efficient. Additionally, it’s important to stay up to date with the latest best practices for query optimization and to test your queries in a development environment before deploying them to production.
Q5. How do you Handle Data Retention and Data Archiving in Redshift?
Handling data retention and data archiving in Amazon Redshift involves several steps:
- Data Retention: Redshift provides the ability to set a retention period for snapshots, which can be used to delete snapshots that are not automatic. This can be used to ensure that you are only retaining the data that you need and to free up disk space.
- Data Archiving: You can use the UNLOAD command to export data from Redshift to S3 and store it in an S3 Glacier or S3 Glacier Deep Archive storage class. This can be useful for archiving data that is not active analysis but needs to be retained for compliance or regulatory reasons.
- Compaction: Redshift allows us to compact tables which we can use to reduce the size of your data and improve query performance.
- Data Governance: You can use Redshift’s data governance features, Resource Access Manager (RAM), and AWS Identity and Access Management (IAM) to control data access and ensure that data is being used in compliance with the policies.
- Data Lifecycle Management: You can use AWS Glue Data Catalog to create, update and delete tables and partitions, set up data retention policies, and archive data.
It’s important to remember that data retention and archiving are ongoing processes. Regularly review your data to ensure that you are retaining only the data you need and that you are archiving data that is not active analysis. Additionally, it’s important for your data archiving and retention processes to ensure that they are working properly and that you can restore your data failure or data loss. This is one of the most frequently asked Amazon Redshift interview questions.
Q6. Explain the Differences between Redshift and other Data Warehousing Solutions like BigQuery?
The last of all Amazon Redshift Interview questions – Amazon Redshift, Snowflake, and BigQuery are all popular data warehousing solutions, but they have some differences that set them apart from each other:
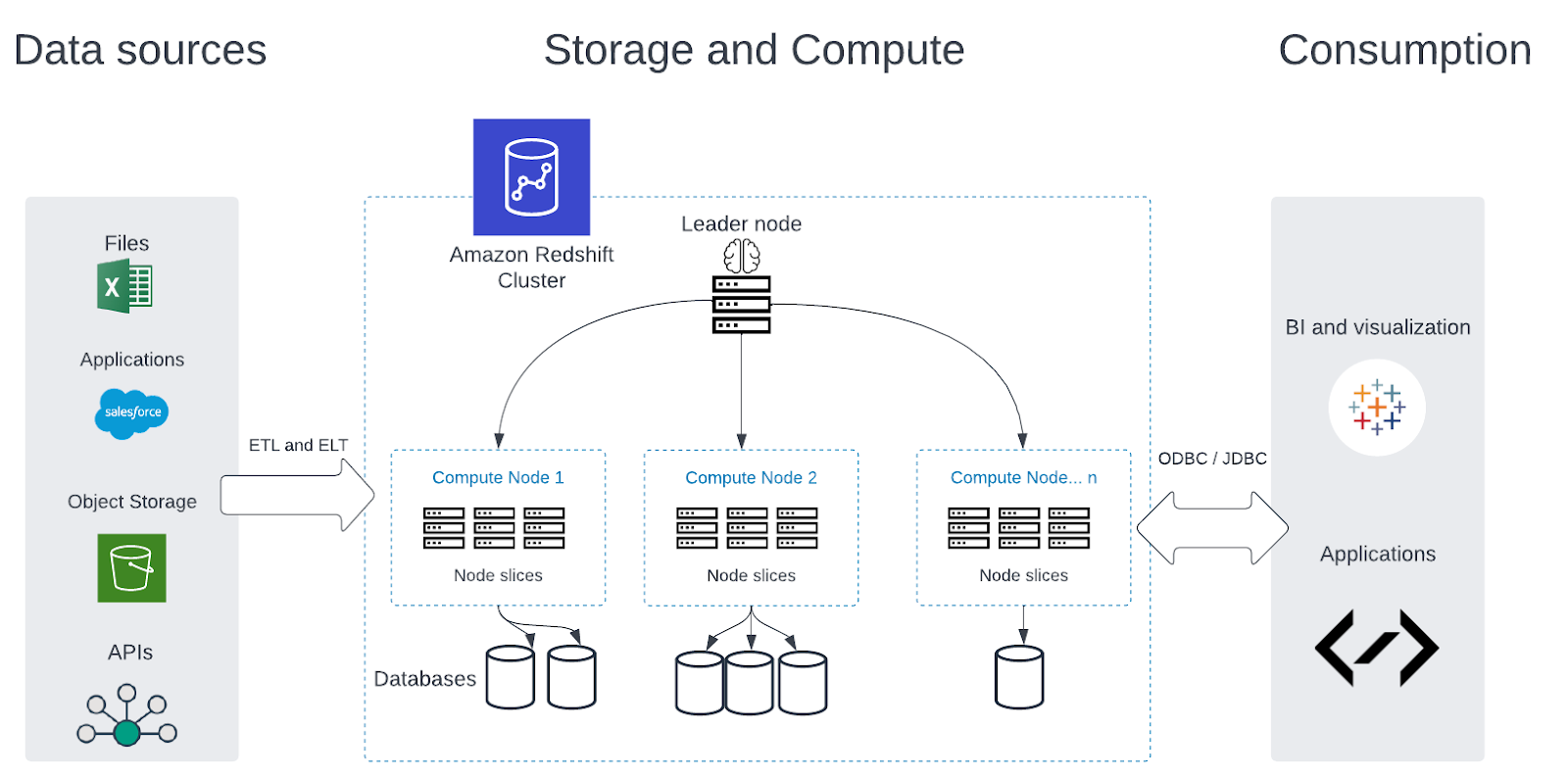
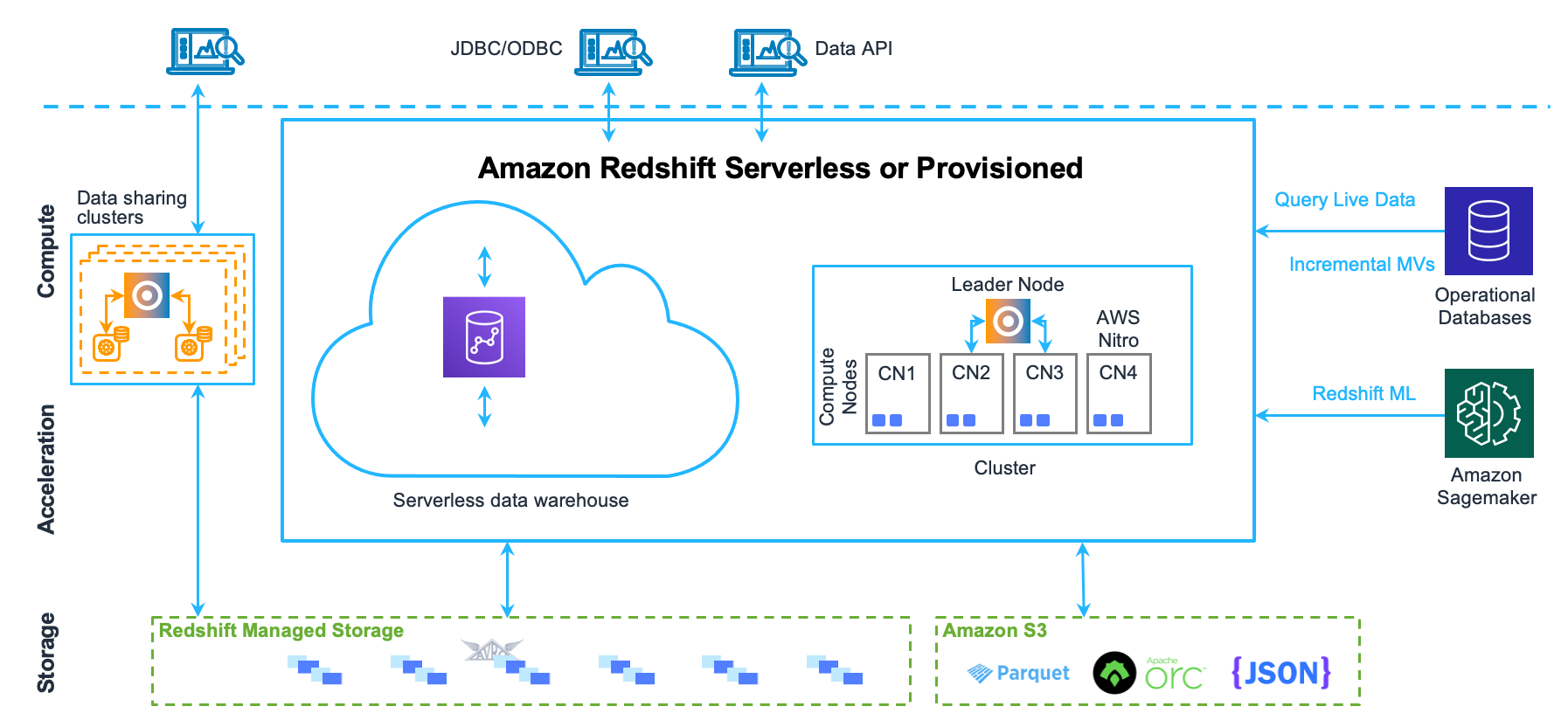
- Architecture: Redshift uses a columnar storage architecture, while Snowflake uses a unique multi-cloud architecture that separates storage and computing. BigQuery uses a combination of columnar storage and row-based processing.
- Scalability: Redshift allows you to scale your group by adding or removing nodes, while Snowflake is completely serverless and automatically scales your computing and storage data as needed. BigQuery can scale your resources up and requires manual intervention.
- Performance: Redshift has strong performance characteristics, especially for complex analytics workloads. Snowflake’s unique architecture is designed to provide high performance and low latency, especially for read-intensive workloads. BigQuery provides fast performance, especially for large-scale data processing and batch queries.
- Pricing: Redshift charges based on the size of your group and the amount of data you store, while Snowflake charges based on the amount of data you store and the compute resources you use. BigQuery charges based on the amount of data you store and the number of queries you run.
- Ease of use: Redshift loading and management tools. Snowflake provides a cloud-based, fully managed solution with a simple. BigQuery provides simple APIs for programmatic access.
Integration with other AWS services: Redshift is fully integrated with other AWS services, S3, Amazon EC2, and Amazon Athena, making it easy to move data between these services. Snowflake provides similar integration with AWS and other cloud providers. BigQuery provides native integration with other Google Cloud services, like Cloud Storage.
Overall, the choice between Redshift, Snowflake, and BigQuery your specific data warehousing needs, including the size and complexity of your data, the performance requirements of your workloads, and your budget. It’s important to evaluate each solution to determine which is best carefully.
Conclusion
In conclusion, Amazon Redshift is a powerful data warehousing service that allows businesses to store, analyze and retrieve large amounts of data cost-effectively. Redshift provides COPY and UNLOAD commands to handle data loading and unloading. To scale and use the “Resize” feature, which allows you to add or remove nodes. To optimize query performance in Redshift, we have to use distribution styles, compression, vacuum, analysis and indexing, and Redshift Query Optimizer. Finally, to handle data retention and archive in Redshift, you can use the UNLOAD command, partitioning, compaction, data governance, and data lifecycle management features. It’s important to remember that all these ongoing tasks must be reviewed and tested to ensure the best performance and security.
Key takeaways of this article:
1. Firstly, we discussed one of the most crucial topics asked in an Amazon Redshift Interview – what Amazon Redshift is and its need and importance.
2. After that, we discussed some common interview-centric questions that can be asked in an Amazon Redshift interview, like scaling the architecture, optimizing the queries, etc.
3. Finally, we discussed the comparison of Redshift with other architectures like BigQuery and then concluded that article. Some youtube links at last, which will help you to understand that topic better.
Video Resources to Reckon
Here are some video resources that you can use to learn about the topics we discussed:
- Overview of Amazon Redshift
- Data loading and unloading in Redshift
- Scaling a Redshift cluster
- Monitoring and troubleshooting performance issues in Redshift
- Implementing security and access control in Redshift
- Handling data replication and backups in Redshift
These videos should provide a good starting point for learning about each topic we discussed. However, as with any video resource, it’s important to read relevant documentation and practice hands-on exercises to gain a deeper understanding of each topic.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
My self Bhutanadhu Hari, 2023 Graduated from Indian Institute of Technology Jodhpur ( IITJ ) . I am interested in Web Development and Machine Learning and most passionate about exploring Artificial Intelligence.






