In this tutorial, I’ll introduce you to anova, its objectives, statistical tests, test examples, statistical analysis, and the different ANOVA techniques used for making the best decisions. We’ll take a few cases and try to understand the techniques for getting the results. We will also be leveraging the use of Excel to understand these concepts.

You must know the basics of anova statistics to understand this topic. Knowledge of t-tests and Hypothesis testing would be an additional benefit. And we believe the best way to learn statistics is by doing. That’s how we follow in the ‘Introduction to Data Science‘ course, where we provide a comprehensive introduction to descriptive and inferential statistics.
Learning Objectives
- In this tutorial, we will learn about Anova and its different types.
- You will familiarize yourself with the different terminologies associated with Anova.
- You will also learn how to calculate Anova In Microsoft Excel.
Table of contents
What is Analysis of Variance (ANOVA)?
Analysis of Variance (ANOVA) is a statistical technique utilized to compare the averages of three or more groups to establish if there are significant statistical differences between them. It accomplishes this by examining the variance (spread) within each group in comparison to the variance among the groups.
Checkout this article about the Hypothesis Testing Made Easy for Data Science
Analysis of Variance (ANOVA)
A common approach to figuring out a reliable treatment method would be to analyze the days the patients took to be cured. We can use a statistical technique to compare these three treatment samples and depict how different these samples are from one another. Such a technique, which compares the samples based on their means, is called ANOVA.
Analysis of variance (ANOVA) is a statistical technique used to check if the means of two or more groups are significantly different from each other. ANOVA checks the impact of one or more factors by comparing the means of different samples. We can use ANOVA to prove/disprove whether all the medication treatments were equally effective.

Another measure to compare the samples is called a t-test. When we have only two samples, t-test, and ANOVA give the same results. However, using a t-test would not be reliable in cases with more than 2 samples. If we conduct multiple t-tests for comparing more than two samples, it will have a compounded effect on the error rate of the result.
How to Use ANOVA in Excel?
Here’s a how to use ANOVA in Excel:
1. Enable Data Analysis Toolpak (if necessary):
- Go to File > Options (or Excel > Preferences on Mac).
- Click on Add-Ins.
- In the Manage dropdown menu, select Excel Add-Ins and click GO.
- Check the box for Analysis ToolPak and click OK.
2. Perform ANOVA:
- Now that the Data Analysis Toolpak is enabled, switch to the Data tab.
- Click on Data Analysis in the Analysis section.
- Choose the appropriate ANOVA test based on your data structure:
- Anova: Single Factor for one categorical independent variable and one continuous dependent variable.
- Anova: Two Factor With Replication for two categorical independent variables and one continuous dependent variable (with equal replications in each group).
3. Setting up the ANOVA Dialog Box:
- Input Range: Select the range of your data, including column headers if you have them.
- Grouped By: Choose “Columns” if you have organized each group in a separate column, or choose “Rows” if you have placed each group in a separate row.
- Labels: Check this box if the first row of your data range contains column headers.
- Alpha: This is the significance level (usually 0.05 by default).
4. Run the Analysis:
- Click OK to run the ANOVA test. Excel will generate an output table with various statistics like Sum of Squares, Degrees of Freedom, and F-statistic to help you assess the significance of differences between your groups.pen_spark
Terminologies Related to ANOVA
Before we start with the ANOVA applications, I would like to introduce some common terminologies used in the technique.
Grand Mean
Mean is a simple or arithmetic average of a range of values. There are two kinds of means that we use in ANOVA calculations, which are separate sample means (μ1,μ2&μ3) and the grand mean (μ).The grand mean is the mean of sample means or the mean of all observations combined, irrespective of the sample.
Hypothesis
Considering our above medication example, we can assume that there are 2 possible cases – either the medication will have an effect on the patients or it won’t. These statements are called Hypothesis. A hypothesis is an educated guess about something in the world around us. It should be testable either by experiment or observation.
Just like any other kind of hypothesis that you might have studied in statistics, ANOVA also uses a Null hypothesis and an Alternate hypothesis. The Null hypothesis in ANOVA is valid when all the sample means are equal, or they don’t have any significant difference. Thus, they can be considered as a part of a larger set of the population. On the other hand, the alternate hypothesis is valid when at least one of the sample means is different from the rest of the sample means. In mathematical form, they can be represented as:

- Null Hypothesis: This states that all the sample means are equal, meaning the factor did not have a significant effect on the results.
- Alternate Hypothesis: This states that at least one of the sample means is different from another. However, it does not specify which one.
- Further Analysis: To identify which specific sample means differ, additional methods will be discussed later in the article.
Between Group Variability
Consider the distributions of the below two samples. As these samples overlap, their individual means won’t differ by a great margin. Hence the difference between their individual and grand means won’t be significant enough.


Such variability between the distributions is called Between-group variability. It refers to variations between the distributions of individual groups (or levels) as the values within each group differ.
Each sample is examined, and the difference between its mean and grand mean is calculated to calculate the variability. If the distributions overlap or are close, the grand mean will be similar to the individual means, whereas if the distributions are far apart, the difference between means and grand mean would be large.

Calculation B/W Group Variability
We will calculate Between Group Variability just as we calculate the standard deviation. Given the sample means and Grand mean, we can calculate it as follows:


We also want to weigh each squared deviation by the sample size. In other words, a deviation is given greater weight if it’s from a larger sample. Hence, we’ll multiply each squared deviation by each sample size and add them. This is called the sum-of-squares for between-group variability.

We must do one more thing to derive a good measure of between-group variability. Again, recall how we calculate the sample standard deviation.
We find the sum of each squared deviation and divide it by the degrees of freedom. For our between-group variability, we will find each squared deviation, weigh them by their sample size, sum them up, and divide by the degrees of freedom (), which in the case of between-group variability is the number of sample means (k) minus 1.

Within Group Variability
Consider the given distributions of three samples. As the spread (variability) of each sample increases, their distributions overlap, and they become part of a big population.

Now consider another distribution of the same three samples but with less variability. Although the means of samples are similar to those in the above image, they seem to belong to different populations

Variations Within – Group
Such variations within a sample are denoted by Within-group variation. It refers to variations caused by differences within individual groups (or levels), as not all the values within each group are the same. Researchers examine each sample individually and calculate the variability among the individual points within the sample. In other words, they do not consider interactions between samples.
SSwithin=∑(xi1−xjˉ)2+∑(xi2−xjˉ)2+…+∑(xik−xjˉ)2=∑(xij−xjˉ)2

Like between-group variability, we then divide the sum of squared deviations by the degrees of freedom  to find a less-biased estimator for the average squared deviation (essentially, the average-sized square from the figure above). Again, this quotient is the mean square, but for within-group variability:
to find a less-biased estimator for the average squared deviation (essentially, the average-sized square from the figure above). Again, this quotient is the mean square, but for within-group variability: 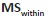 . This time, the degrees of freedom is the sum of the sample sizes (N) minus the number of samples (k). Another way to look at degrees of freedom is that have the total number of values (N) and subtract 1 for each sample
. This time, the degrees of freedom is the sum of the sample sizes (N) minus the number of samples (k). Another way to look at degrees of freedom is that have the total number of values (N) and subtract 1 for each sample


F-Statistic (F-test)
The statistic that measures whether the means of different samples are significantly different is called the F-Ratio. The lower the F-Ratio, the more similar will the sample means be. In that case, we cannot reject the null hypothesis.
F = Between-group variability / Within-group variability
This above formula is pretty intuitive. The numerator term in the F-statistic calculation defines the between-group variability. As we read earlier, the sample means to grow further apart as between-group variability increases. In other words, the samples are likelier to belong to different populations.
This F-statistic calculated here is compared with the F-critical value for concluding. In terms of our medication example, if the value of the calculated F-statistic is more than the F-critical value (for a specific α/significance level), then we reject the null hypothesis and can say that the treatment had a significant effect.


Therefore, there is only one critical region in the right tail (shown as the blue-shaded region above). If the F-statistic lands in the critical region, we can conclude that the means are significantly different, and we reject the null hypothesis. Again, we must find the critical value to determine the cut-off for the critical region. We’ll use the F-table for this purpose.
We need to look at different F-values for each alpha/significance level because the F-critical value is a function of two things: df within and df between.
One Way ANOVA or Single Factor Anova
As we now understand the basic terminologies behind ANOVA, let’s dive deep into its implementation using a few examples.
A recent study claims that music in a class enhances the concentration and consequently helps students absorb more information. As a teacher, your first reaction would be skepticism.
What if it affected the results of the students in a negative way? Or what kind of music would be a good choice for this? Considering all this, it would be immensely helpful to have some proof that it actually works.
Figure For three different Classes
To figure this out, we implemented it on a smaller group of randomly selected students from three different classes. The idea is similar to conducting a survey. We took three different groups of ten randomly selected students (all of the same age) from three different classrooms. Each classroom was provided with a different environment for students to study. Classroom A had constant music being played in the background, classroom B had variable music being played, and classroom C was a regular class with no music playing. After one month, we conducted a test for all the three groups and collected their test scores. The test scores that we obtained were as follows:

Now, we will calculate the means and the Grand mean.
So, in our case, 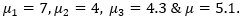

Looking at the above table, we might assume that the mean score of students from Group A is definitely greater than the other two groups, so the treatment must be helpful. Maybe it’s true, but there’s also a slight chance that we randomly selected the best students from class A, leading to better test scores. This raises a few questions, such as:
- How do we decide that these three groups performed differently because of the different situations and not merely by chance?
- In a statistical sense, how different are these three samples from each other?
- What is the probability of group A students performing differently than the other two groups?
To answer all these questions, we first calculate the F-statistic, which we express as the ratio of Between Group variability to Within Group Variability.

Let’s complete the ANOVA test for our example with α = 0.05.
Read about this article Feature Selection Using Statistical Tests
Limitations of One-Way ANOVA
A one-way ANOVA tells us that at least two groups are different from each other. But it won’t tell us which groups are different. If our test returns a significant f-statistic, we may need to run a post-hoc test to tell us exactly which groups differ in means. Below I have mentioned the steps to perform one-way ANOVA in Microsoft Excel along with a post-hoc test.
Step-by-Step to Perform One-Way ANOVA With Post-hoc Test
- Input your data into columns or rows in Excel. For example, if three groups of students for music treatment are being tested, spread the data into three columns.
- Click the “Data” tab and then click “Data Analysis.” If you don’t see Data Analysis, load the ‘Data Analysis Toolpak’ add-in.
- Click “ANOVA Single Factor” and then click “OK.”
- Type an input range into the Input Range box. For example, if the data is in cells A1 to C10, type “A1:C10” into the box. Check the “Labels in the first row” if we have column headers, and select the Rows radio button if the data is in rows.
- Select an output range. For example, click the “New Worksheet” radio button.
- Choose an alpha level. For most hypothesis tests, 0.05 is standard.
- Click “OK.” The results from ANOVA will appear in the worksheet.
- The results for our example look like this:

Here, we can see that the F-value is greater than the F-critical value for the alpha level selected (0.05). Therefore, we have evidence to reject the null hypothesis and say that at least one of the three samples have significantly different means and thus belongs to an entirely different population.
Another measure for ANOVA is the p-value. If the p-value is less than the alpha level selected (which it is, in our case), we reject the Null Hypothesis.
Methods for Finding Two Different Populations
There are various methods for finding out which samples represent two different populations. I’ll list some for you:
We won’t be covering all of these here in this article, but I suggest you go through them.
Now to check which samples had different means, we will take the Bonferroni approach and perform the post hoc test in Excel through following steps:
Step 8: Again, click on “Data Analysis” in the “Data” tab and select “t-Test: Two-Sample Assuming Equal Variances,” and click “OK.”
Step 9: Input the range of Class A column in Variable 1 Range box and range of Class B column in Variable 2 Range box. Check the “Labels” if you have column headers in the first row.
Step 10: Select an output range. For example, click the “New Worksheet” radio button.
Step 11: Perform the same steps (Step 8 to step 10) for Columns of Class B – Class C and Class A – Class C.
The results will look like this:


Voila! The music experiment actually helped in improving the results of the students.
One-Way ANOVA Calculation
Another effect size measure for one-way ANOVA is called Eta squared. It works in the same way as R2 for t-tests. We can use it to calculate how much proportion of the variability between the samples is due to the between-group difference. It is calculated as:

For the above example:

Hence 60% of the difference between the scores is because of the approach that was used. Rest 40% is unknown. Hence, the Eta square helps us conclude whether the independent variable really impacts the dependent variable or whether the difference is due to chance or any other factor.
There are commonly two types of ANOVA tests for univariate analysis – One-Way ANOVA and Two-Way ANOVA. Researchers use one-way ANOVA to examine the impact of a single independent variable (IDV)/factor on a population. In contrast, researchers employ Two-way ANOVA to study the simultaneous effects of two factors on a population. For multivariate analysis, researchers apply MANOVA, or Multi-variate ANOVA.
Two-Way ANOVA
Using one-way ANOVA, we found out that the music treatment helped improve the test results of our students. But this treatment was conducted on students of the same age. What if the treatment was to affect different age groups of students in different ways? Or maybe the treatment had varying effects depending upon the teacher who taught the class.
Moreover, how can we be sure which factor(s) is affecting the students’ results more? Maybe the age group is a more dominant factor responsible for a student’s performance than the music treatment.
For such cases, researchers use a slightly modified technique called two-way ANOVA because two independent variables/factors affect the outcome or dependent variable (in this case, the test scores). In the one-way ANOVA test, we found that the group subjected to ‘variable music’ and ‘no music at all’ performed more or less equally. It means that the variable music treatment did not have any significant effect on the students.
So, while performing two-way ANOVA, we will not consider the “variable music” treatment for simplicity of calculation. Rather a new factor, age, will be introduced to find out how the treatment performs when applied to students of different age groups. This time our dataset looks like this:

Two Factors of ANOVA
Here, there are two factors – class and age groups with two and three levels, respectively. So we now have six different groups of students based on different permutations of class groups and age groups, and each different group has a sample size of 5 students.
A few questions that two-way ANOVA can answer about this dataset are:
- Is music treatment the main factor affecting performance? In other words, do groups subjected to different music differ significantly in their test performance?
- Is age the main factor affecting performance? In other words, do students of different ages differ significantly in their test performance?
- Is there a significant interaction between the factors? In other words, how do age and music interact with regard to a student’s test performance? For example, it might be that younger and older students reacted differently to such a music treatment.
- Can researchers find differences in one factor within another? In other words, do researchers find differences in music and test performance across different age groups?
Two-way ANOVA tells us about the main effect and the interaction effect. The main effect is similar to a one-way ANOVA, where researchers measure the effects of music and age separately. In comparison, the interaction effect is where researchers consider both music and age simultaneously.
two-way ANOVA can have up to three hypotheses, which are as follows:
Two null hypotheses will be tested if we have placed only one observation in each cell. For this example, those hypotheses will be:
H1: All the music treatment groups have an equal mean score.
H2: All the age groups have an equal mean score.
For multiple cell observations, we would also test a third hypothesis:
H3: The factors are independent, or the interaction effect does not exist.
F-Statistic for Each Hypothesis
An F-statistic is computed for each hypothesis we are testing.
Before proceeding with the calculation, look at the image below. It will help us better understand the terms used in the formulas.

The table shown above is known as a contingency table. Here, 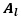 it represents the total of the samples based only on factor 1 and
it represents the total of the samples based only on factor 1 and 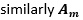 represents the total of samples based only on factor 2. We will see in some time that these two are responsible for the main effect produced. Also, a term
represents the total of samples based only on factor 2. We will see in some time that these two are responsible for the main effect produced. Also, a term 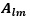 is introduced representing the subtotal of factor 1 and factor 2. This term will be responsible for the interaction effect produced when both the factors are considered simultaneously. And we are already familiar with the
is introduced representing the subtotal of factor 1 and factor 2. This term will be responsible for the interaction effect produced when both the factors are considered simultaneously. And we are already familiar with the  , which is the sum of all the observations (test scores), irrespective of the factors.
, which is the sum of all the observations (test scores), irrespective of the factors.

Calculation of all the Means
We have calculated all the means – sound class mean, age group mean, and mean of every group combination in the above table.
Now, calculate the sum of squares (SS) and degrees of freedom (df) for sound class, age group, and interaction between factor and levels.
We already know how to calculate SS (within)/df (within) in our one-way ANOVA section, but in two-way ANOVA, the formula is different. Let’s look at the calculation of two-way ANOVA:


In two-way ANOVA, we also calculate SSinteraction and dfinteraction, which defines the combined effect of the two factors.

Since we have more than one source of variation (main effects and interaction effects), it is obvious that we will have more than one F-statistic also.
Using these variances, we compute the value of F-statistic for the main and interaction effect. So, the values of f-statistic are,
F1 = 12.16
F2 = 15.98
F12 = 0.36
We can see the critical values from the table
Fcrit1 = 4.25
Fcrit2 = 3.40
Fcrit12 = 3.40
Suppose for a particular effect, its F value is greater than its respective F-critical value (calculated using the F-Table). In that case, we reject the null hypothesis for that particular effect.
Steps to Perform Two-Way ANOVA in Excel 2013
Step 1: Click the “Data” tab and then click “Data Analysis.” If you don’t see the Data analysis option, install the Data Analysis Toolpak.
Step 2: Click “ANOVA two factor with replication” and then click “OK.” The two-way ANOVA window will open.
Step 3: Type an Input Range into the Input Range box. For example, if your data is in cells A1 to A25, type “A1:A25” into the Input Range box. Ensure you include all of your data, including headers and group names.
Step 4: Type a number in the “Rows per sample” box. Rows per sample is actually a bit misleading. What this is asking you is how many individuals are in each group. For example, if you have 5 individuals in each age group, you would type “5” into the Rows per Sample box.
Step 5: Select an Output Range. For example, click the “new worksheet” radio button to display the data in a new worksheet.
Step 6: Select an alpha level. In most cases, an alpha level of 0.05 (5 percent) works for most tests.
Step 7: Click “OK” to run the two-way ANOVA. The data will be returned in your specified output range.
Step 8: Read the results. To figure out if you are going to reject the null hypothesis or not, you’ll basically be looking at two factors:
- If the F-value (F)is larger than the f critical value (F crit)
- If the p-value is smaller than your chosen alpha level.
And you are done!
Note: We don’t only have to have two variables to run a two-way ANOVA in Excel 2013. We can also use the same function for three, four, five, or more variables.
Results for DataSet Test
The results for two-way ANOVA test on our example look like this:

As you can see in the highlighted cells in the image above, the F-value for sample and column, i.e., factor 1 (music) and factor 2 (age), respectively, are higher than their F-critical values. This means that the factors significantly affect the students’ results, and thus we can reject the null hypothesis for the factors.
Also, the F-value for interaction effect is quite less than its F-critical value, so we can conclude that music and age did not have any combined effect on the population.
Multi-Variate ANOVA (MANOVA)
Until now, we have been making conclusions about the performance of students based on just one test. Could there be a possibility that the music treatment helped improve the results of a subject like mathematics but would affect the results adversely for a theoretical subject like history?
How can we ensure the treatment won’t be biased in such a case? So again, we take two groups of randomly selected students from a class and subject each group to one kind of music environment, i.e., constant music and no music. But now we thought of conducting two tests (maths and history), instead of just one. This way, we can be sure how the treatment would work for different subjects.
We can say that one IDV/factor (music) will be affecting two dependent variables (maths scores and history scores) now. This kind of problem comes under a multivariate case; the technique we will use to solve it is known as MANOVA. Here, we will work on a specific case called one-factor MANOVA. Let us now see how our data looks:

Here we have one factor, music, with 2 levels. This factor will affect our two dependent variables, i.e., the test scores in maths and history. Denoting this information in terms of variables, we can say that we have L = 2 (2 different music treatment groups) and P = 2 (maths and history scores).
A MANOVA test also takes into consideration a null hypothesis and an alternate hypothesis.:

The Calculations of MANOVA are too complex for this article, so if you want to further read about it, check this paper. We will implement MANOVA in Excel using the ‘RealStats’ Add-ins. It can be downloaded from here.
Steps to Perform MANOVA in Excel 2013
1 Step: Download the ‘RealStats’ add-in from the link mentioned above
2 Step: Press “control+m” to open RealStats window
3 Step: Select “Analysis of variance”
4 Step: Select “MANOVA: single factor”
5 Step: Type an Input Range into the Input Range box. For example, if your data is in cells A1 to A25, type “A1:A25” into the Input Range box. Make sure you include all of your data, including headers and group names.
6 Step: Select “Significance analysis”, “Group Means” and “Multiple Anova”.
7 Step: Select an Output Range.
8 Step: Select an alpha level. In most cases, an alpha level of 0.05 (5 percent) works for most tests.
9 Step: Click “OK” to run. The data will be returned in your specified output range.
10 Step: Read the results. To figure out if you are going to reject the null hypothesis or not, you’ll basically be looking at two factors:
- If the F-value (F)is larger than the f critical value (F crit)
- If the p-value is smaller than your chosen alpha level.
And you are done!

RealStats Different Methods
RealStats add-on shows us the results by different methods. Each one of them denotes the same p-value. We will reject the null hypothesis because the p-value is less than the alpha value. Or in simpler terms, it means that the music treatment did have a significant effect on students’ test results.
But we still cannot determine which subjects the treatment affected and which it did not. This is one of the limitations of MANOVA; even if it tells us whether a factor significantly affects a population, it does not tell us which dependent variable the factor actually affects.
For this purpose, we will see the “Multiple ANOVA” table to generate a helpful summary. The result will look like this:

Here, we can see that the P value for history lies in a significant region (since P value is less than 0.025) while for maths, it does not. This means that the music treatment had a significant effect in improving the performance of students in history but did not have any significant effect in improving their performance in maths.
Based on this, we might consider picking and choosing subjects where this music approach can be used.
Conclusion
I hope this article was helpful, and now you’d be comfortable solving similar problems using Analysis of Variance (ANOVA). I suggest you take different kinds of problem statements and take your time to solve them using the above-mentioned techniques.
Hope you get a clear understanding of ANOVA, or analysis of variance, which helps compare means among three or more groups. To do an ANOVA test in Excel, use the Data Analysis ToolPak. ANOVA in statistics checks if differences between groups are significant. ANOVA explained is about comparing the variation within and between groups. How to do ANOVA in Excel is simple: select your data and run the ANOVA analysis tool. This method is crucial in ANOVA statistics for making informed decisions based on your data.
You should also check out the below two resources to give your data science journey a huge boost:
Key Takeaways
- Researchers use ANOVA, a statistical formula, to compare variances across the means (or averages) of different groups.
- There are two types of commonly used ANOVA; one-way ANOVA and two-way ANOVA.
- To analyze variance (ANOVA), statisticians or analysts use the f-test to compute the feasibility of variability amongst two groups more than the variations observed within the said groups under study.
Frequently Asked Questions
Q1. What is ANOVA used for in Excel?
A. In Excel, ANOVA is a built-in statistical test used to analyze the variances. For instance, we usually compare the available alternatives when buying a new item, which eventually helps us choose the best from all the available options.
Q2. What do you mean by Analysis of Variance?
A. ANOVA is a statistical test used to compare the means of multiple groups. It determines if there are significant differences between these means.
Q3. What is the name of the Excel function for ANOVA?
A. ANOVA is not a function in Excel. In Microsoft Excel, ANOVA is part of Excel’s “Data Analysis” tool.
Q4. What is difference between T test and ANOVA?
T-test: Compares the means of two groups.
ANOVA: Compares the means of three or more groups.pen_spark







The alternative hypothesis may be better stated as "at least a pair of means is different"
Great and pleasant explanation of Anova. Thanks!
Thank you Aletta. Happy Learning :)
I found the explanation of the 1 way anova great, but couldn't follow the 2 way anova at all. Also is this for repeated measures anova or between participants? I hear they are very different mathematically.
Hey Thomas The basic intuition behind One way Anova is to determine the effects of Music treatment on the scores of the students. Similarly in Two way Anova, we determine the effects of 2 variables (Age, Music) on the score of the students. In addition we also check for combined effect of these two variables. In regards to your other query, this is not repeated measures Anova. Repeated measures Anova involves determining the effect of independent variables on the same sample ie determining the effect of music on the same sample of students. This could be done by determining the scores of students without music and comparing it with scores of same students with music treatment.