This article was published as a part of the Data Science Blogathon.
Introduction
Success is a process not an event.
What’s harder than understanding the concepts of Data Science? Proving to your interviewer that you actually understand them! The interview process can be daunting and often involves a mix of theoretical, problem-solving, and behavioral assessment questions. In this article, we have included 20 essential questions and their answers that you must know before going for your Data Science interview.
Ready for your mock-up Data Science interview?

The most important concepts and interview questions are as follows :
1. What is Linear Regression? What are the Assumptions involved in it?
Answer: The question can also be phrased as to why linear regression is not a very effective algorithm.
Linear Regression is a mathematical relationship between an independent and dependent variable. The relationship is a direct proportion, relation making it the most simple relationship between the variables.
Y = mX+c
Where:
- Y is the Dependent Variable
- X is the Independent Variable
- m and c are constants
Assumptions of Linear Regression :
- The relationship between Y and X must be Linear.
- The features must be independent of each other.
- Homoscedasticity – The variation between the output must be constant for different input data.
- The distribution of Y along X should be the Normal Distribution.
2. What is Logistic Regression? What is the loss function in LR?
Answer : Logistic Regression (or LR) is a supervised learning algorithm that is used for binary classification tasks. It predicts the probability of the occurence of an event where there are only two possible outcomes. Such outcomes can be represented as 0 or 1, such as ‘yes’ or ‘no’, ‘true’ or ‘false’, or ‘spam’ or ‘not spam’ etc.
Logistic Regression works by applying sigmoid funtion to a linear combination of input features:
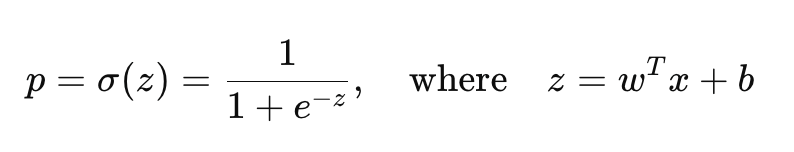
Here, w represents the weights, x the input features, and b the bias term. The sigmoid function squashes the output into a probability between 0 and 1.
The loss function in LR is the Binary Cross-Entropy Loss also known as the Log Loss function. This function measures the differnece between the predicted probility and the actual class label. The equation for which is given as :
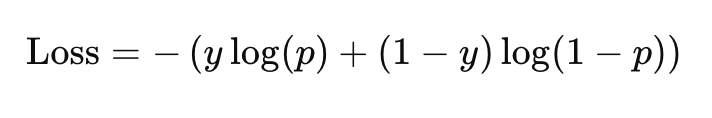
Where:
- y is the true label (0 or 1)
- p is the predicted probablity for Class 1
This function penalises wrong predictions more strongly, the more confident they are, making it appropriate for probablistic models.
3. Difference between Regression and Classification?
Answer: The major difference between Regression and Classification is that Regression results in a continuous quantitative value while Classification is predicting the discrete labels.
However, there is no clear line that draws the difference between the two. We have a few properties of both Regression and Classification. These are as follows:
Regression
- Regression predicts the quantity.
- We can have discrete as well as continuous values as input for regression.
- If input data are ordered with respect to the time it becomes time series forecasting.
Classification
- The Classification problem for two classes is known as Binary Classification.
- Classification can be split into Multi-Class Classification or Multi-Label Classification.
- We focus more on accuracy in Classification while we focus more on the error term in Regression.
4. Define variance and conditional variance.
Variance, denoted by Var(X), quantifies the spread of a single random variable from its expected value or mean. It measures how far are a set of numbers are speard out from their average value. A higher value of variance indicates that the data points are very spread out from their mean value while a lower value of variance implies that the data points are placed close to the mean value.
Conditional Variance, denoted by Var (X|Y = y) gives a measure of the variance of a random variable X when the value of another random variable Y is given to be y. In simple words, it calculates the variance of a subset of the data that meets a specified condition. It is useful in understanding the correlation between two variables; exploring how the uncertainty of one variable changes when we have information about another.
5. Why do we need Evaluation Metrics? What do you understand by the Confusion Matrix?
Answer: Evaluation Metrics are statistical measures of model performance. They are very important because to determine the performance of any model it is very significant to use various Evaluation Metrics. A few of the evaluation Metrics are – Accuracy, Log Loss, and Confusion Matrix.
Confusion Matrix is a matrix to find the performance of a Classification model. It is in general a 2×2 matrix with one side as prediction and the other side as actual values.

6. How does Confusion Matrix help in evaluating model performance?
Answer: Evaluation Metrics are statistical measures of model performance. They are very important because to determine the performance of any model it is very significant to use various Evaluation Metrics.
Few of the evaluation metrics are:
- Accuracy
- Log Loss
- Confusion Matrix
Confusion Matrix:
Confusion Matrix is a matrix to find the performance of a Classification model.
It is generally a 2×2 matrix with one side representing predictions and the other side representing actual values.
7. What is the significance of Sampling? Name some techniques for Sampling?
Answer: For analyzing the data we cannot proceed with the whole volume at once for large datasets. We need to take some samples from the data which can represent the whole population. While making a sample out of complete data, we should take that data which can be a true representative of the whole data set.
There are mainly two types of Sampling techniques based on Statistics: Probability Sampling and Non Probability Sampling. These are
- Probability Sampling – In this technique every data point has a known, non-zero chance of being selected.
- Simple Random
- Clustered Sampling
- Stratified Sampling.
2. Non-Probability Sampling – In this technique, not all data points have a guaranteed chance of selection.
- Convenience Sampling
- Quota Sampling
- Snowball Sampling.
8. What are Type 1 and Type 2 errors? In which scenarios the Type 1 and Type 2 errors become significant?
Answer: Rejection of a true null hypothesis is known as a Type 1 error. In simple terms, False Positives are known as a Type 1 Error.
Not rejecting a false null hypothesis is known as a Type 2 error. False Negatives are known as Type 2 Errors.
- Type 1 Error: is critical when false positives can cause harm.
Example: A man not suffering from a disease is incorrectly diagnosed as positive. The unnecessary medication might damage his organs. - Type 2 Error: is significant when false negatives can lead to missed alerts.
Example: A bank alarm system fails to detect an actual burglary, treating it as a false alarm, which results in a major loss.
9. What are the conditions for Overfitting and Underfitting?
Answer: Overfitting and Underfitting are common issues in machine learning that affect a model’s ability to generalize.
Overfitting occurs when a model learns the training data too well, including noise and outliers. As a result, it performs well on training data but poorly on unseen data.
- Condition: Low bias and High variance
- Example: Decision Trees are prone to overfitting if not pruned or regularized.
Underfitting happens when a model is too simple to capture the underlying patterns in the data, leading to poor performance on both training and test sets.
- Condition: High bias and Low variance
- Example: Linear Regression may underfit complex non-linear data.
10. What do you mean by Normalisation? Difference between Normalisation and Standardization?
Answer: Normalisation is a process of bringing the features in a simple range so that the model can perform well and not get inclined towards any particular feature.
For example: If we have a dataset with multiple features and one feature is the Age data which is in the range 18–60, another feature is the salary feature ranging from 20,000 – 2,000,000. In such a case, the values are very much different in them. Age ranges in two-digit integers while salary is in a range significantly higher than the age. So to bring the features in a comparable range we need Normalisation.
Both Normalisation and Standardization are methods of Features Conversion. However, the methods are different in terms of the conversions.
- The data after Normalisation scales are in the range of 0–1.
- In the case of Standardization, the data is scaled such that its mean comes out to be 0.
11. What do you mean by Regularisation? What are L1 and L2 Regularisation?
Answer: Regulation is a method to improve your model which is Overfitted by introducing extra terms in the loss function. This helps in making the model performance better for unseen data.
There are two types of Regularisation:
L1 Regularisation – In L1 we add lambda times the absolute weight terms to the loss function. In this, the feature weights are penalized on the basis of absolute value.
L2 Regularisation – In L2 we add lambda times the squared weight terms to the loss function. In this, the feature weights are penalized on the basis of squared values.
12. Describe the Decision tree Algorithm and what are entropy and information gain.
Answer: A Decision Tree is a supervised machine-learning algorithm used for classification and regression tasks. It works by splitting the dataset into subsets based on the most significant attribute at each node, creating a tree-like model of decisions.
The algorithm starts at the root node and recursively splits the data using a metric-like information gain until it reaches a leaf node, which represents a final class label (for classification) or value (for regression).
Entropy is a measure of impurity or randomness in the data. It quantifies how mixed the class labels are within a dataset.
- Low entropy means the data is mostly of one class (pure).
- High entropy means the data has mixed classes (impure).
Information Gain measures the reduction in entropy after a dataset is split on an attribute. The goal of the decision tree is to maximize information gain at each split.
The attribute with the highest information gain is selected for splitting.
13. What is Ensemble Learning? Give an important example of Ensemble Learning.
Answer: Ensemble Learning is a process of accumulating multiple models to form a better prediction model. In Ensemble Learning, the performance of the individual model contributes to the overall development in every step. There are two common techniques in this – Bagging and Boosting.
Bagging: In this, the dataset is split to perform parallel processing of models, and results are accumulated based on performance to achieve better accuracy.
Boosting: This is a sequential technique in which a result from one model is passed to another model to reduce error at every step, making it a better performance model.
The most important example of Ensemble Learning is the Random Forest Classifier. It takes multiple Decision Trees combined to form a better-performance Random Forest model.
14. Explain the Naive Bayes Classifier and the principle on which it works.
Answer: Naive Bayes Classifier is a probabilistic machine learning algorithm based on Bayes’ Theorem. It assumes that features are conditionally independent given the class label, which is why it is called “naive.”
The algorithm calculates the posterior probability of each class given the input features and predicts the class with the highest probability.
Bayes’ Theorem expresses the conditional probability of an event based on prior knowledge of related events:
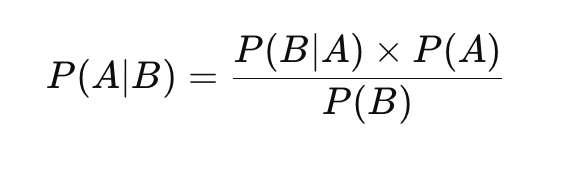
Where:
- P(A|B) is the posterior probability of class A given feature B.
- P(B|A) is the likelihood of feature B given class A.
- P(A) is the prior probability of class A.
- P(B) is the prior probability of feature B.
Despite its simplifying assumption of feature independence, Naive Bayes performs well in many practical applications such as text classification and spam detection.
15. What is Imbalanced Data? How do you manage to balance the data?
If data is distributed across different categories and the distribution is highly imbalanced, such data are known as Imbalanced Data. These kinds of datasets cause errors in model performance by making the category with large values more significant for the model, resulting in an inaccurate model.
There are various techniques to handle imbalanced data:
- Increasing the number of samples for minority classes
- Decreasing the number of samples for classes with extremely high numbers of data points
- Using cluster-based techniques to increase the number of data points for all categories
16. Explain the Unsupervised Clustering approach.
Answer: Unsupervised clustering is a technique used to group data points into clusters based on inherent similarities without using labeled data. The aim is to discover hidden patterns or structures in the data.
There are several clustering approaches:
- Density-Based Clustering (e.g., DBSCAN, HDBSCAN): Clusters are formed based on areas of high density separated by low-density regions.
- Hierarchical Clustering: Builds a tree of clusters by either merging smaller clusters (agglomerative) or splitting larger clusters (divisive).
- Partition-Based Clustering: Divides data into a predefined number of clusters (e.g., K-Means).
- Distribution-Based Clustering: Assumes data is generated from a mixture of distributions and clusters are identified accordingly.
This approach helps in data exploration, pattern recognition, and preprocessing for other tasks.
17. Explain the DBSCAN Clustering technique and in what terms DBSCAN is better than K- Means Clustering.
Answer: DBSCAN (Density-Based) clustering technique is an unsupervised approach that splits the vectors into different groups based on the minimum distance and number of points lying in that range. In DBSCAN Clustering we have two significant parameters:
- Epsilon: The minimum radius or distance between the two data points to tag them in the same cluster.
- Min Sample Points: The number of minimum samples that should fall under that range to be identified as one cluster.
DBSCAN Clustering technique has a few advantages over other clustering algorithms:
- In DBSCAN, we do not need to provide a fixed number of clusters. There can be as many clusters formed based on the data points distribution. While in K-Nearest Neighbors (KNN), we need to provide the number of clusters to split our data into.
- In DBSCAN, we also get a noise cluster identified which helps us in identifying the outliers. This sometimes also acts as a significant term to tune the hyperparameters of a model accordingly.
18. What do you mean by Cross Validation? Name some common Cross-Validation techniques.
Answer: Cross Validation is a model performance improvement technique. This is a statistics-based approach in which the model gets to train and be tested with rotation within the training dataset so that the model can perform well for unknown or testing data.
In this, the training data are split into different groups and in rotation those groups are used for validation of model performance.
The common Cross Validation techniques are:
- K-Fold Cross Validation
- Leave p-out Cross Validation
- Leave-one-out Cross Validation
- Holdout Method
19. What is Deep Learning ?
Answer: Deep Learning is the branch of Machine Learning and AI which tries to achieve better accuracy and is able to build complex models. Deep Learning models are similar to human brains in structure, with input layers, hidden layers, activation functions, and output layers designed to mimic the brain’s architecture.
Deep Learning has many real-time applications:
- Self Driving Cars
- Computer Vision and Image Processing
- Real Time Chatbots
- Home Automation Systems
20 . Difference between RNN and CNN?
| Aspect | CNN (Convolutional Neural Network) | RNN (Recurrent Neural Network) |
|---|---|---|
| Data Type | Best for spatial data like images | Best for sequential data like text or time series |
| Typical Use Cases | Image classification, object detection | Sentiment analysis, language modeling, time-series forecasting |
| Architecture | Feedforward; processes input all at once | Recurrent; processes input step-by-step with memory |
| Sequence Handling | Cannot model time/order dependencies | Maintains memory to model temporal patterns |
| Training Speed | Fast and parallelizable | Slower, due to sequential nature |
| Gradient Issues | Generally stable | Prone to vanishing and exploding gradients |
| Popular Variants | ResNet, VGG, EfficientNet | LSTM, GRU |
Conclusion
These questions are derived specifically for the Data Science context from multiple interview experiences and also covered in our certification in Data Science. However, it’s recommended apart from these questions to practice the coding skills, SQL, Data Engineering questions, Statistics Questions, and ETL tools questions. Also, understanding the end-to-end Data Science solution from Data extraction to Final UI. These are all the desired skills to be a perfect Data Scientist. Users can put questions in the comments for any further clarifications.
Read more:
Top 100 Data Science Interview Questions and Answers
90+ Python Interview Questions and Answers
Top 40 Machine Learning Interview Questions & Answers
I am a Data Science expert with excellent understanding of NLP and its applications. I work in Finance domain supporting Data Science use cases and mentor people who are interested in Data Science and Analytics







I secured 8 passes grade in my BTech, Oils, UDCT-Mumbai. Sir. Gopalakrishnan Kumar.