This article was published as a part of the Data Science Blogathon.
Introduction
In this article, we shall explore the process of deriving the optimal coefficients for a simple logistic regression model. Most of us might be familiar with the immense utility of logistic regressions to solve supervised classification problems. Some of the complex algorithms that we use today are largely a sophisticated version of logistic regression. How do we implement logistic regression for a model?
For those of us with a background in using statistical software like R, it’s just a calculation done using 2-3 lines of codes (e.g., the glm function in R). However, that makes it sound like a black box. You input your data, some hidden calculations go on and you get the coefficients that you can use to make predictions. But data science isn’t just about coding or getting results. It’s also about understanding mathematics and the theory, decoding those black boxes, and appreciating each step of the computation process. We shall attempt to do the same here: demystify the process by which our statistical software computes the optimal coefficients for logistic regression. To do so, we shall use a very powerful statistical tool called maximum likelihood estimation (MLE). Those that are interested in knowing more about this tool, can check out this article. We will still walk through the basics of MLE in this article. Let’s begin by revising the logistic function and understanding some of its properties.
Primitives of the Logistic Function
The equation for the standard logistic function is given by:
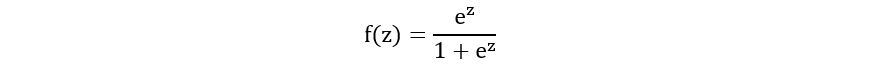
Graphically, it can be visualized as:
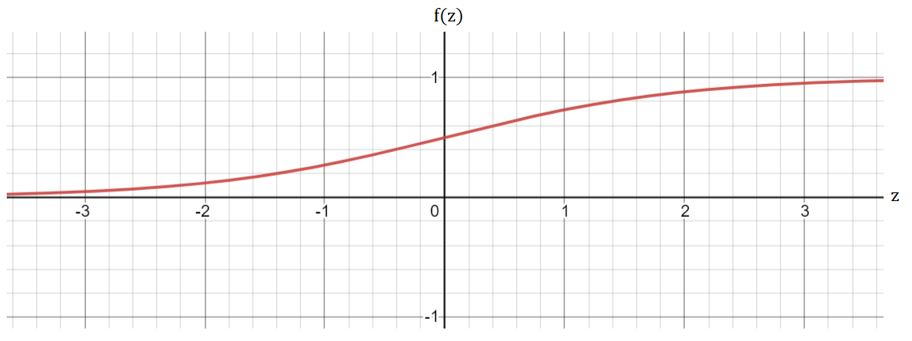
There are 2 horizontal asymptotes: y = 0 and y = 1:
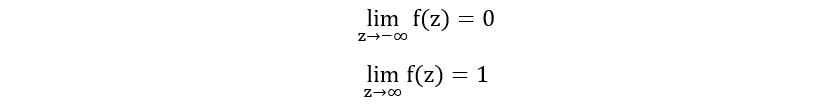
In any proposed model, to predict the likelihood
of an outcome, the variable z needs to be a
function of the input or feature variables X1, X2,
…, Xp. In logistic regression, z is often expressed as a linear function of the input
variables as follows:
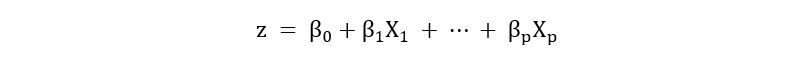
Thus, the probability that a binary outcome variable y = f(z) takes the value of the positive class (1) is given by:
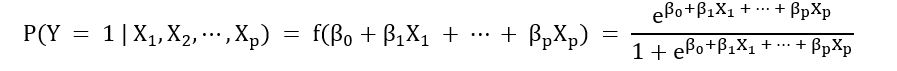
For a simple logistic regression, we consider only 2 parameters: β0 and β1 and thus only 1 feature X. Thus, we have:
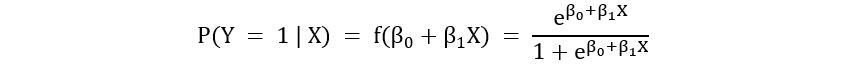
Note that we have used the notation of conditional probability in the above equation. You may just think of it as the probability that the outcome variable belongs to the positive class (Y = 1), given the feature (conditional on the value of the feature) X. Suppose we have the data of n observations (y1, y2, …, yn) and (x1, x2, …, xn). How do we estimate β0 and β1? Let’s first take a slight detour and tackle a very simple example using maximum likelihood estimation:
The Example of Coin Toss: Bernoulli Distribution
Suppose we have a coin, and we need to estimate the probability that it lands on the heads. Naturally, the first thing to do would be to toss it several times (say, n times) and note down the results (as binary outcomes: 1 for heads and 0 for tails). Suppose we record the observations as (y1, y2, …, yn). We might then be tempted to find the sample mean of the observations and use it as an estimate for the probability of landing heads. So, if we get 3 heads and 7 tails in 10 tosses, we might conclude that the probability of landing heads is 0.3. Let’s see if we can use rigorous mathematics to confirm our intuition:
Let’s first identify the probability distribution of the coin toss
example. Since the outcome variable is
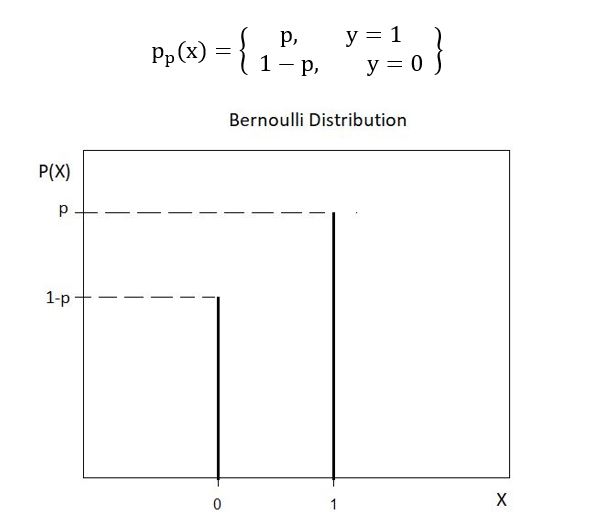
binary- 0 and 1, it follows a Bernoulli distribution. Bernoulli distribution is a discrete distribution having two
possible outcomes- 1 (success) with a probability p & 0 (failure) with
probability (1-p). The probability mass function of a Bernoulli distribution is
defined as:
Often, the above function is simplified to a single line equation as follows:
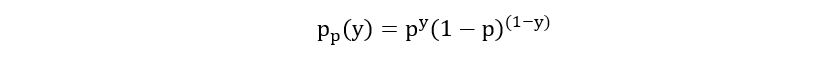
We’ll now define the likelihood function for our distribution. In general, the likelihood function is defined as follows for discrete random variables as follows:
If Y1, Y2, …, Yn are identically distributed random variables belonging to a probability distribution ℙθ, where θ is an unknown parameter characterizing the distribution (e.g., the parameter p of Bernoulli distribution), then the likelihood function is defined as:
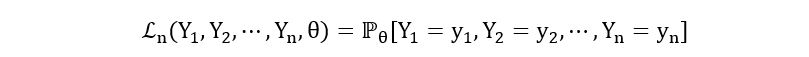
Furthermore, if Y1, Y2, …, Yn are independent,
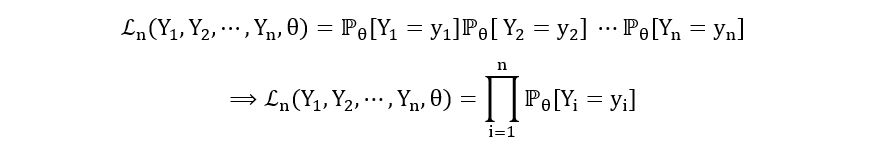
Here, ℙθ[Yi=yi] is the probability that the random variable Yi takes the value yi. By definition of probability mass function, if Y1, Y2, …, Yn have probability mass function pθ(y), then, ℙθ[Yi=yi] = pθ(yi). So, we have:
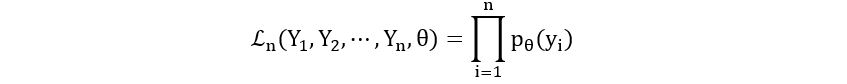
Using this we can compute the likelihood function of the coin toss problem:
Parameter: θ=p
Probability Mass Function:
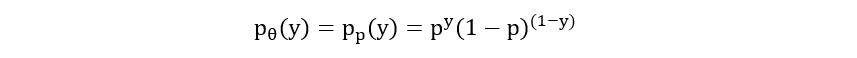
Likelihood Function:
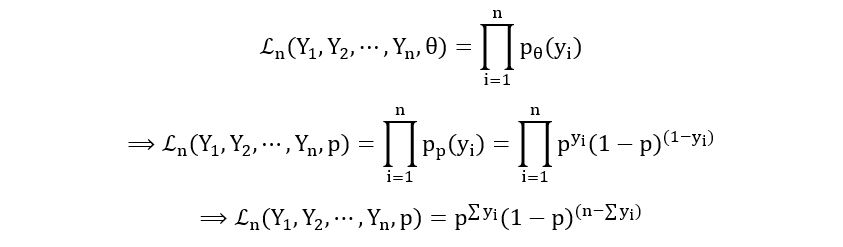
Now that we have the likelihood function, we can easily find the maximum likelihood estimator for the parameter p. The MLE is defined as the value of θ that maximizes the likelihood function:
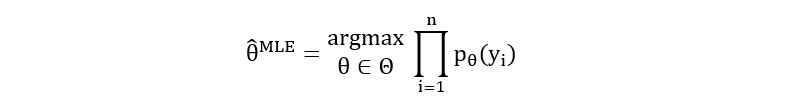
Note
that Θ refers to the parameter space i.e., the range of values the unknown
parameter θ can take. For our case, since p indicates the probability that the
coin lands as heads, p is bounded between 0 and 1. Hence, Θ = [0, 1]. We can use
the tools of calculus to maximise the likelihood function. However, it’s often
very tricky to take the derivatives. So, we use logarithmic differentiation by calculating
the log-likelihood function and maximizing it instead of the likelihood
function. Since log x is an increasing function,
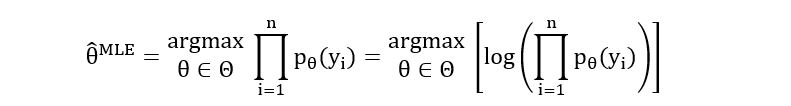
Now that we’re equipped with the tools of maximum likelihood estimation, we can use them to find the MLE for the parameter p of Bernoulli distribution:
Likelihood Function:
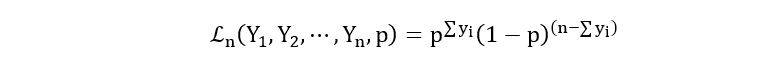
Log-likelihood Function:
Maximum Likelihood Estimator:
Calculation of the First derivative:
Calculation of Critical Points in (0, 1):
Calculation of the Second derivative:
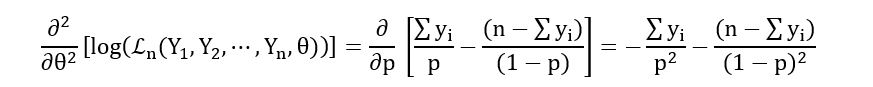
Substituting the estimator we obtained earlier in the above expression, we obtain,
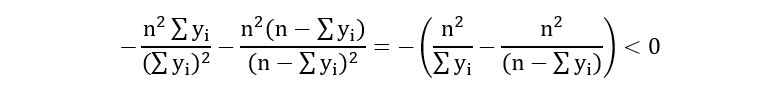
Therefore, p = 1/n*(sum(yi)) is the maximiser of the log-likelihood.
Therefore,
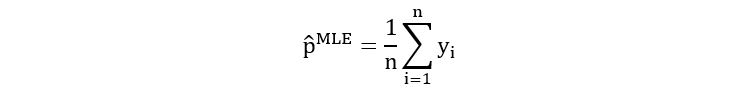
Yes, the MLE is the sample-mean estimator for the Bernoulli distribution. Isn’t it amazing how something so natural as a simple intuition could be confirmed using rigorous mathematical formulation and computation! We can now use this method of MLE to find the regression coefficients of the logistic regression.
Using MLE for the Logistic Regression Model
Let’s first attempt to answer a simple question: what the probability distribution for our problem is? Is it the logistic function that we talked about earlier? Nope. It’s again the Bernoulli distribution. The only difference from the previous case is that this time the parameter p (probability that Y = 1) is the output of the logistic function. The data that we have is inputted into the logistic function, which gives the output:
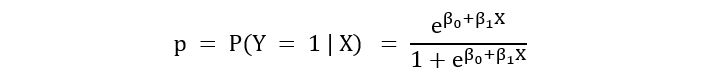
We can make the above substitution in the probability mass function of a Bernoulli distribution to get:
Parameters: θ = [β0, β1]
Probability Mass Function:
Likelihood Function:
Log-likelihood Function:
Now that we’re derived the log-likelihood function, we can use it to determine the MLE:
Maximum Likelihood Estimator:
Unlike the previous example, this time we have 2 parameters to optimise instead of just one. Thus, we’ll have to employ tools in the domain of multivariable calculus (gradients and partial derivatives) to solve our problem. We maximize the multi-dimensional log-likelihood function as follows:
Computing the Gradient of the Log-likelihood:

Setting the gradient equal to the zero vector, we obtain,
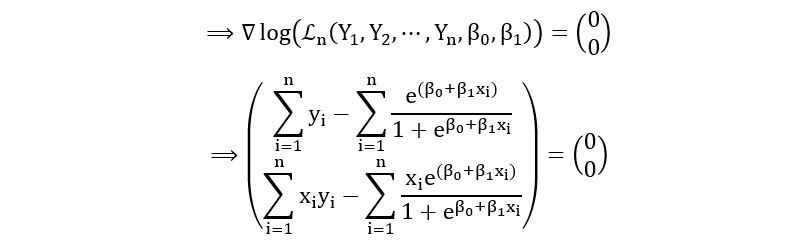
On comparing the first element, we obtain:
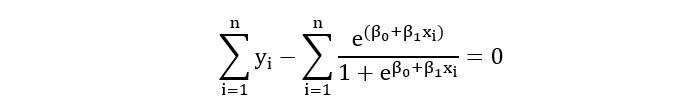
On comparing the second element, we obtain:
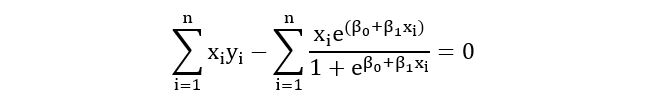
Thus, we have obtained the maximum likelihood estimators for the parameters of the logistic regression in the form of a pair of equations. Note that, there is no closed-form solution for the estimators. The solutions to the above pair of equations can be computed using various mathematical algorithms e.g., the Newton Raphson algorithm. You may read more about the algorithm here.
Solved Example
Finally, to make some more sense of all the math we did, let’s plug in some real numbers. Suppose we have the following data where xi is a measure of a person’s credit score and yi indicates whether the person has been offered a bank loan. To simplify the calculations and the analysis, we have considered the case for only 3 customers:

Let’s first use R to perform the calculations. We will then compare the results obtained by R with those obtained by using our equations:
x <- c(-10,1,3) y <- c(1,0,1) fit <- glm(y ~ x, family = binomial(link = "logit")) coef(fit)

Now, we’ll use the equations we derived:
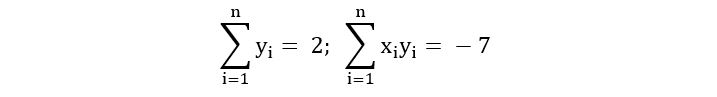
Thus, we have the following set of score equations:
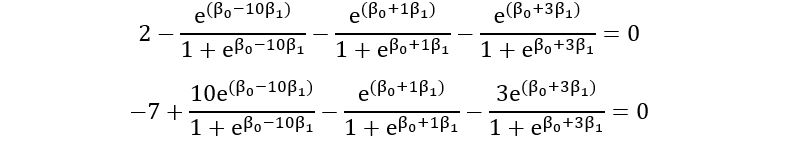
We can plot the above equations to solve them graphically:
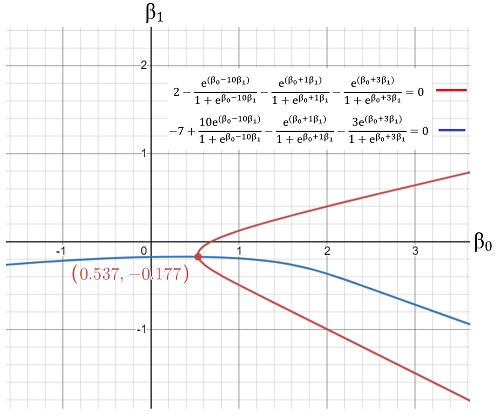
The intersection of the 2 graphs gives us the optimal value of the coefficients: (0.537, -0.177). Voila! That’s incredibly close. Thus, we have been able to successfully use the tools of calculus and statistics to decode the computation processes that determine the coefficients of logistic regression.
Conclusion
In this article, we explored the theory and mathematics behind the process of deriving the coefficients for a logistic regression model. To do so, we used the method of MLE, by first going through the example of a simple coin toss and then generalizing it for our problem statement. Finally, we illustrated the application of the statistical theory utilized by taking the example of a loan eligibility prediction problem.
We’ve taken the case of a simple logistic regression (with 1 feature variable) to elucidate the process. For cases with more than 1 feature, the process remains the same. It just become lengthier. So, for p feature variables, we will have p +1 coefficients that can be obtained by solving a system of p + 1 equations. I
hope you enjoyed going through this article!
In case you have any doubts or suggestions, do reply in the comment box. Please feel free to contact me via mail.
If you liked my article and want to read more of them, visit this link.
Note: All images have been made by the author.
About the Author

I am currently a first-year undergraduate student at the National University of Singapore (NUS), who is deeply interested in Statistics, Data Science, Economics and Machine Learning. I love working on different Data Science projects. If you’d like to see some of my projects, visit this link.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.







Wonderful Naman ‘! Vikas Garg Solicitor Senior Courts of England & Wales United Kingdoms
Wonderful Naman ! Vikas Garg Solicitor Senior Courts of England & Wales United Kingdoms
Is there any ML which can help predict box size for products?