
Source: Canva
Introduction
Researchers of Google Ai recently introduced a text-based transformer hyperparameter optimization (HPO) framework called OptFormer that offers a unified end-to-end interface for jointly learning the policy and function priors when trained on a wealth of tuning data gathered from the wild, e.g., the Google Vizier database, which is one of the world’s largest HPO datasets. Experiments illustrate that the OptFormer can imitate a minimum of seven different HPO algorithms, which can be improved further using its function uncertainty estimates. Compared to a Gaussian Process, the OptFormer also learns a robust prior distribution for hyperparameter response functions, allowing it to give more accurate and well-calibrated predictions. This work sets the way for future extensions to train a Transformer-based model as a broad HPO optimizer.
This article will look at the proposed Hyperparameter optimization (HPO) framework at length. Now, let’s delve in!
Highlights
• Researchers of Google AI proposed a text-based Transformer HPO framework that offers a unified end-to-end interface for jointly learning policy and function prediction when trained on data across different search spaces.
• The OptFormer can learn the behaviours of seven black-box optimization algorithms that use a diverse set of approaches (non-adaptive, evolutionary, and Bayesian).
• OptFormer also learns the priors over objective functions and yields accurate and well-calibrated predictions, outperforming Gaussian Processes (GPs) in log-predictive likelihood and predicted calibration error in many circumstances (ECE).
• OptFormer policies reinforced with model-based optimization, such as using expected Improvement acquisition functions, are competitive HPO algorithms.
Method Overview
Leveraging the T5X codebase, the OptFormer is trained in a typical encoder-decoder style using standard generative pretraining over a variety of hyperparameter optimization objectives, including real-world data gathered by Google Vizier, as well as public hyperparameter (HPO-B) and blackbox optimization benchmarks (BBOB).
Rather than just using numerical data, OptFormer employs concepts from natural language. A serialization scheme is introduced to transform a combination of metadata and an optimization trajectory into text, represented as a sequence of tokens. The HPO task as a sequence modelling problem is formulated. It learns to predict parameters and hyperparameter response functions from offline tuning data in a supervised-learning manner (See Fig. 1). To further improve the optimization performance, the model is augmented by its function prediction during inference.
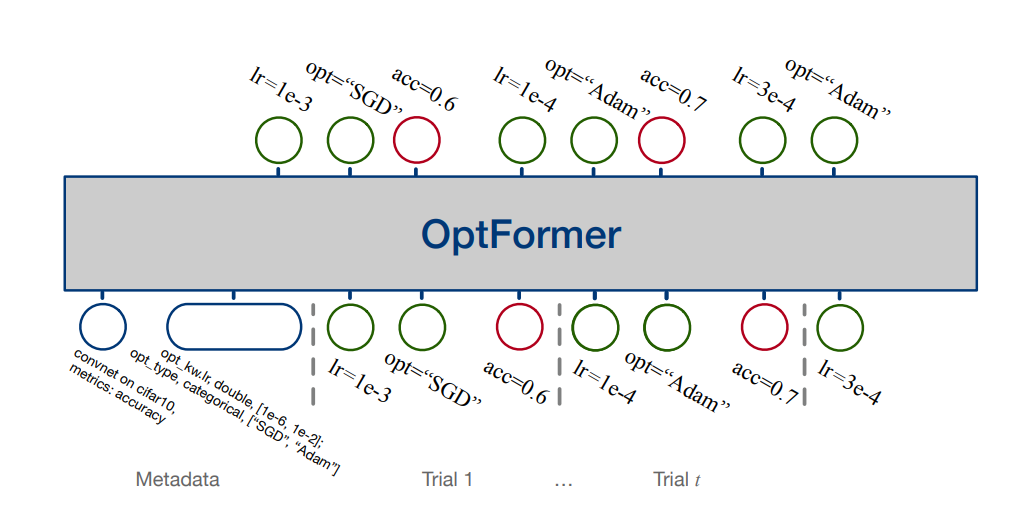
Figure 1: Illustration of the OptFormer model over a hyperparameter optimization (HPO) trajectory. It predicts hyperparameter suggestions (in green) and response function values (in red).
In the animation below, OptFormer initially observes text-based metadata (shown in the grey box), including details like the title, search space parameter names, and metrics to optimize, which OptFormer utilizes to output the parameter and objective value predictions repeatedly. For instance, in the animation shown below, OptFormer observes “CIFAR10”, “learning rate”, “optimizer type”, and “Accuracy”, which informs the OptFormer of an image classification task. It then suggests new hyperparameters to try on the task, predicts the task accuracy, and then receives the true accuracy, which is subsequently used for generating hyperparameters for the next round. 
Results
A single Transformer model with 250M parameters was trained on the union of the three datasets: RealWorldData, HPO-B, and BBOB, to predict the conditional distributions of parameter and function values.
Majorly, the following three questions were addressed:
- Can the OptFormer learn to mimic various HPO algorithms using a single model?
The OPTFORMER was evaluated for its ability to learn the conditional distribution of parameter suggestions provided by the behavior policies in the dataset, as well as its ability to imitate multiple algorithms. Because the name of the algorithm is contained in the metadata m, the behavior of the policy πprior(xt+1|m, ht) can be easily modified by altering this variable.
Fig. 2 compares the average and standard deviation of the best-normalized function values at trial 100. The OptFormer imitates most algorithms very accurately in both the mean and variance except for the most complicated algorithm, Vizier, where πprior is slightly worse in the LUNACEK benchmark. And since Vizier is the best performing HPO algorithm, the OptFormer imitates Vizier faithfully, although not perfectly.
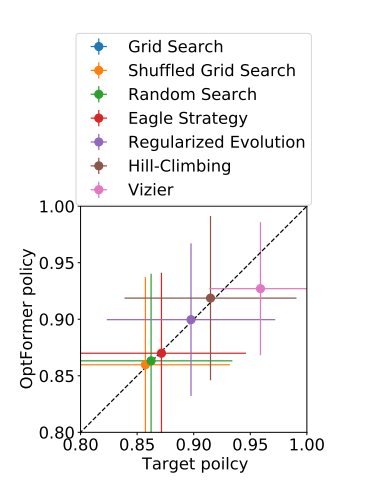
Figure 2: Average best function at trial 100 with standard deviation.
2. Is it possible for the OptFormer to learn a good prior over hyperparameter response functions?
The log-predictive likelihood log p(yt|xt, . . .) and ECE on RealWorldData and HPO-B test sets are reported in Table 1. From Table 1, it can be inferred that the OptFormer achieves better predictive likelihood and ECE than the GP on both datasets.
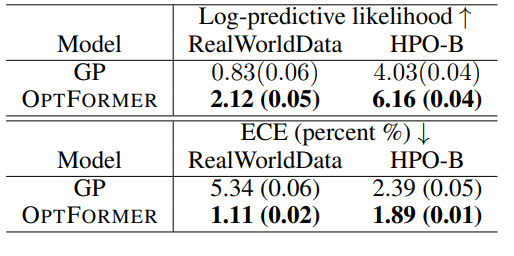
Table 1: Log-predictive likelihood (with 1-std. standard error, higher is better (↑)) and ECE (percentage of error, lower is better (↓)) on RealWorldData and HPO-B test sets.
3. Is OptFormer a viable approach for HPO?
OptFormer was evaluated as a hyperparameter optimization algorithm on two benchmarks, RealWorldData and HPO-B. Three transfer learning methods based on multi-task GP models were included: ABLR, FSBO, and HyperBO. However, it’s worth noting that these three transfer learning methods can not be applied to real-world data in particular since they need learning GPs on multiple tasks sharing the same search space.
Figure 3 depicts the trajectory of the best-normalized function value averaged across all functions from each benchmark. While the prior policy returned by the OptFormer doesn’t outperform Vizier, it is still comparable to or slightly better than the GP-UCB baseline and ABLR.
The most remarkable improvement is obtained when the prior policy is augmented with the Expected Improvement acquisition function. The resulting OptFormer (EI) outperforms all baselines on both benchmarks. It was noted that the OptFormer could learn the distribution of functions in the meta-training split, transfer it to the meta-testing split, and exhibit good generalization performance beyond the optimization window it is trained for.
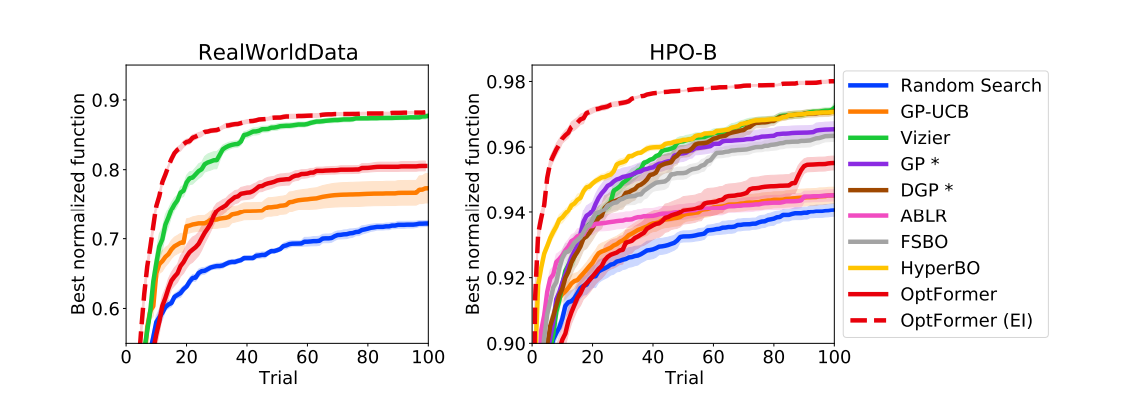
Figure 3: Best normalized function value averaged over 16 RealWorldData test functions (left) and over 86 HPO-B test functions (right) with 1-std confidence interval from 5 runs.
Limitations and Future Work
1. The parameters that are not always applicable or are subject to dynamic constraints depending on other parameter values were not considered. The proposed method can be modified to AutoML and NAS-like applications in the future by providing conditional specifications as text in metadata.
2. Only sequential optimization with a batch size of 1 was considered. To support parallel suggestions, random masking of input function value observations could be used to simulate scenarios with parallel pending trials.
3. While the Transformer was trained to clone the behaviour policy offline, offline RL could be applied too. Furthermore, meta-training acquisition functions within
the same model and online fine-tuning could be incorporated.
4. A single objective function was considered, though multiple objectives can be included by outputting multiple function tokens in a trial.
Conclusion
To summarize, in this article, we learned the following:
1. A text-based Transformer HPO framework was proposed that offers a unified end-to-end interface for jointly learning policy and function prediction when trained on large-scale datasets containing tuning experiments with diverse search spaces and experiment descriptions.
2. By training on a diverse set of synthetic and real-world tuning trajectories, a single Transformer model can imitate 7 fundamentally different HPO policies, learn to make well-calibrated few-shot function predictions and provide competitive optimization performance on unseen test functions compared with the existing, long-tried Gaussian Process (GP) based baselines.
3. The most remarkable improvement is obtained when the prior policy is augmented with the Expected Improvement acquisition function. The OptFormer (EI) outperforms all baselines on RealWorldData and HPO-B benchmarks.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I'm a Researcher who works primarily on various Acoustic DL, NLP, and RL tasks. Here, my writing predominantly revolves around topics related to Acoustic DL, NLP, and RL, as well as new emerging technologies. In addition to all of this, I also contribute to open-source projects @Hugging Face.
For work-related queries please contact: [email protected]






