This article was published as a part of the Data Science Blogathon.
Introduction
Healthcare is an important part of human lives. It is also another sector that has been disrupted by technology. In many parts of the world, billions of clinical and laboratory activities are carried out, producing tons of data. Data science is an emerging field of science that is still rapidly growing. A lot has been seen in the sciences, yet statistics believe it has barely begun. Since there is huge data, data science can strive. With all the promises of MLOps and the delicate nature of health care, merging the two is a research area that needs more work.
Unlike other areas of applying data science, health requires more carefulness and research. The rapid growth of data science has also caused some instability in standards and operations. There is a lack of a universal harmonized pattern for a unison that controls the lifecycle of data production and management down to modeling and deployment. Tech has found its way into health in diverse ways where data science is only one, using fields like medical imaging, predictive diagnosis, and several others. Yet, there is weakness in global research unison. This presents a need to be able to deploy and manage machine learning models for use in the clinical workflow.
The common statistic is that around 90% of models never make it to production, which leaves just 10% to manage. Fair enough. This implies even lesser of this 10 percent is in the health sector for a health data scientist to manage. To do this, it becomes a requirement to utilize comprehensive MLOps. The Data Scientist has to carry out a workflow that will improve health outcomes by integrating regular DevOps procedures and enormous volumes of data from health sources, developing and monitoring model performance.
The Benefit of MLOps in Health
In traditional medicine, medical practitioners manually inspect and examine images with their eyes to find complications. This stood at the mercy of human accuracy and experience. Using Computer Vision in deep learning and data science could save these disadvantages and provide a more accurate diagnosis.
The job of a doctor looks very similar to the data analysis procedures. The Doctor looks at the patient for insights using the variables he can find. He gathers these variables and says the most likely possibility as his result. This should be that simulating the health sector should be very typical and therefore promising.
If MLOps is researched by sector and health is given its sector, the promises are endless. Predictive analytics will become so comfortable and highly effective. It is one of the most popular areas in health analytics.
We do not call the doctor’s results a prediction but rather a diagnosis. This is because the word prediction sounds too unsafe. Yet what doctors do most at times from physical diagnoses and even tests and scans is the prediction from what they have found. This is why sometimes the other chances of the probability results in the patient coming up with a different experience from the doctor’s diagnosis. This is like in predictive models, where the model predicts falsely due to another reason. In the doctor’s case, it may be a human error from his sight or measuring materials during observation or tests. Or even a low skill set. A predictive model will use historical data, learn from it, find patterns, and make predictions from it, just like a doctor who has learned from past patients who failed to survive an operation and can predict the likeliness of success of the next operation.
A health data science system that can utilize good MLOps stands a good chance of outperforming some of the best human medical practitioners. Just as AI games have outshined some of the coolest human game grandmasters, it can happen in health. This could cut costs and save time. This presents both preventive measures and corrective measures for human health. And what could be better than a world with such medical advancement?
The Job of a Healthcare Data Scientist
As you may have thought, the job of a health data scientist is more demanding. It can easily become a very complex one. Domain knowledge is vital in all areas of Data Science. It comes with many necessary skills and responsibilities. Apart from mathematical, statistical, and programming skills, health data scientists need a level of medical knowledge and understanding of the healthcare industry. The role of any data scientist, regardless of the domain, is to collect, collate and report on data.
Due to patient privacy and regulatory compliance, the Health Insurance Portability and Accountability Act of 1996 (HIPAA) and the Payment Card Industry (PCI) make it quite complex to run a data job. The Data Scientist is expected to develop and deploy models using a robust MLOps framework that adheres to protocols and privacy regulations.
Healthcare data scientists will develop forecasting and modeling programs designed to form analyses of medical records and health information. As usual, the DS will need to look for insights or make models but in health, the scientist focuses more on directly replicating a medical doctor by simply making diagnoses and prescriptions.
As a healthcare data scientist using MLOps, you could work in a more organized workflow. From developing tools for collecting data, to analyzing this information, these are medical records, documents like health insurance, billing, etc., and building models for identifying patterns or trends in the data and recommending ways to use the information to improve the system with robust models. It goes to the point of making these models ready to use and maintain.
MLOps Framework for Healthcare
Let us see a Machine learning workflow for a health domain. It shows how robust the MLOps is generally and in a critical sector such as healthcare. The model-building pipeline helps achieve the following:
- Versioning of the health data; Data production in health systems is likely nonstatic. Even after collecting data and starting a development cycle, new data may still be created from the working environment since the hospital has not shut down its system and activities. This brings a need to tag these different sets of produced data. The dataset has to be handled accordingly and appended with additional data using the best procedures. Data versioning is the means by which all the changes are tracked over time.
- Health Data validation; Data validation is essential in handling the entire project to make sense. In Medicine, it is important to undergo the process of ensuring that the data has undergone the process to ensure data quality making it useful.
- Efficient Data preprocessing; Data preprocessing describes the activity of raw data to prepare it for other data processing. Data preprocessing is needed to manipulate or remove unwanted contents of the data before it is used for production to ensure a better performance.
- Effective training of machine learning model; After the previous activities are done the model can then be trained to be able to learn from the health data and be useful for insights.
- Keeping track of model training; Training the model is not enough yet. There needs to be further activity in monitoring the model training process. This is the edge of MLOps. More detail is given to the life cycle of Ml making the results more robust.
- Analyzing and validating trained and tuned models; This is another advantage of using MLOps, unlike regular training and testing, we also check if the model is valid. If it is not then it is tuned to meet ends. Model validation is will evaluate whether the model’s outputs are reasonable. Data that appear to make sense is critically checked for sense to avoid misleading results and enhance relevance.
- Deploying the validated model; After we are sure the model is well-trained, tested, and validated with fine-tuning where necessary, it can be put into production. The health system can now have a system working for their needs and more. The data scientist could still use the model or be useable directly by medical practitioners.
- Scaling the deployed model; Everything would have been settled now in a regular machine learning workflow, but with MLOps, we still continue with the cycle by calling. Scaling will allow the model to be adjusted even yet to new needs that may arise that were not addressed. This is robustness; hence the model is now scalable.
- Capturing new training data and model performance: This stage works with versioning to ensure the new data is captured and reused like a loop. Imagine someone uses a model and they input their own data to get results. This data is still saved for continuous upgrade of the model, making it better even after it has been deployed.
The above points show that MLOps is robust and welcome in all M-learning sectors that use Mlearning.
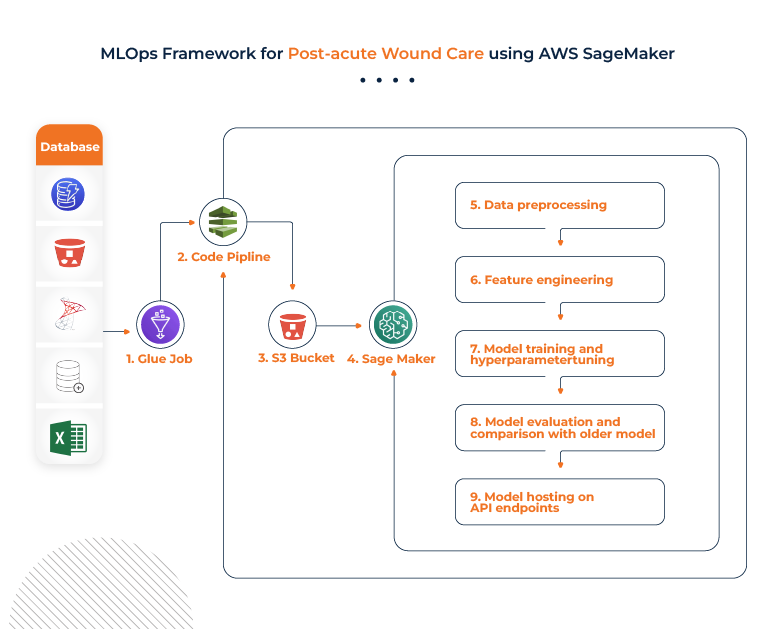
Using MLOps for Post-acute Wound Care
TheMathCompany presents an approach for post-acute wound care. The following image outlines the MLOps model that would streamline the process for the post-acute space:


1. Develop a machine learning model (predicts wound healing time) that is robust and dynamic while still maintaining a level of generality across defined categories of wound-level factors.
2. Integrate patient- and visit-level factors into the model as they significantly influence the independent variable across the defined wound-level categories.
3. Add the complete machine learning model – after monitoring, adjusting, and validating it – using live EHR data, without re-integrating the results into the EHR until appropriate efficacy is confirmed. The model will then predict wound healing time to create a more accurate predictive tool.
4. Use the wound healing time model to produce a dynamic and predictive healing trajectory.
5. Concurrently develop a “progress” metric representing weighted wound-level variables that contribute to measuring and determining change over time, thus defining a solid metric for “outcome”.
6. Measure the effect and intervention of treatment by tracking the progress and noting the variables that change over time. This will determine the optimal treatment plan given any constellation of wound-level factors (i.e., wound type, severity, anatomic location), patient-level factors (i.e., comorbidities, medication), and visit-level factors (i.e., BMI determinations, lab results.) Then, introduce a production pilot once acceptable efficacy is established through monitoring, analysis, and adjustment.
7. Attach cost variables to the dressings and interventions used so that the EHR can concurrently determine clinical outcomes and cost-effectiveness. It can also include a hybrid of these factors for a data-driven treatment recommendation engine that augments physician decision-making.
Conclusion
Health Data Science is an emerging discipline. A Health Data Scientist using tools and skills of data science to manage and analyze huge, diverse datasets across healthcare systems. As per typical, the DS will need to conduct research or develop models, but in the field of health, the scientist focuses more on accurately simulating a physician by merely prescribing diagnoses and treatments. Data analysis processes appear to be very similar to a doctor’s work. The doctor examines the patient for insights using the factors at his disposal. He compiles these variables and comes up with the most likely scenario as his conclusion. The health industry should be highly typical and so very promising when simulated.
Key takeaways:
- Traditional medical practitioners manually inspect and examine images with their eyes to find complications at the mercy of human accuracy.
- If MLOps is researched by sector and health is given its sector, the promises are endless. Predictive analytics will become very effective. Predictive analysis is a common area in health analytics.
- A health data science system that can utilize good MLOps stands a good chance of outperforming some of the best human medical practitioners, just as AI games have outshined some of the coolest human game grandmasters.
- Healthcare data scientists could work more organized using MLOps. From developing tools for collecting data, to analyzing medical records, documents like health insurance, billing, etc., and building models for identifying trends in the data and recommending ways to use the information to improve the system.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am an AI Engineer with a deep passion for research, and solving complex problems. I provide AI solutions leveraging Large Language Models (LLMs), GenAI, Transformer Models, and Stable Diffusion.






