Feature Scaling is a critical step in building accurate and effective machine learning models. One key aspect of feature engineering is scaling, normalization, and standardization, which involves transforming the data to make it more suitable for modeling. These techniques can help to improve model performance, reduce the impact of outliers, and ensure that the data is on the same scale. In this article, we will explore the concepts of scaling, normalization, and standardization, including why they are important and how to apply them to different types of data. By the end of this article, you’ll have a thorough understanding of these essential feature engineering techniques and be able to apply them to your own machine learning projects. Also in the article you will get to know about the data standardization vs normalization and with these difference you will get clear understanding of feature scaling.
In this article, you will learn about feature scaling, its importance in machine learning, and how scaling in machine learning can enhance model performance.
Table of contents
- What is Feature Scaling?
- Why Use Feature Scaling?
- What is Normalization?
- What is Standardization?
- The Big Question – Normalize or Standardize?
- Implementing Feature Scaling in Python
- Comparing Unscaled, Normalized, and Standardized Data
- Applying Scaling to Machine Learning Algorithms
- Frequently Asked Questions
What is Feature Scaling?
Feature scaling is a preprocessing technique that transforms feature values to a similar scale, ensuring all features contribute equally to the model. It’s essential for datasets with features of varying ranges, units, or magnitudes. Common techniques include standardization, normalization, and min-max scaling. This process improves model performance, convergence, and prevents bias from features with larger values.
Why Use Feature Scaling?
Some machine learning algorithms are sensitive to feature scaling, while others are virtually invariant. Let’s explore these in more depth:
Gradient Descent Based Algorithms
Machine learning algorithms like linear regression, logistic regression, neural network, PCA (principal component analysis), etc., that use gradient descent as an optimization technique require data to be scaled. Take a look at the formula for gradient descent below:

The presence of feature value X in the formula will affect the step size of the gradient descent. The difference in the ranges of features will cause different step sizes for each feature. To ensure that the gradient descent moves smoothly towards the minima and that the steps for gradient descent are updated at the same rate for all the features, we scale the data before feeding it to the model.
Distance-Based Algorithms
Distance algorithms like KNN, K-means clustering, and SVM(support vector machines) are most affected by the range of features. This is because, behind the scenes, they are using distances between data points to determine their similarity.
For example, let’s say we have data containing high school CGPA scores of students (ranging from 0 to 5) and their future incomes (in thousands Rupees):

Since both the features have different scales, there is a chance that higher weightage is given to features with higher magnitudes. This will impact the performance of the machine learning algorithm; obviously, we do not want our algorithm to be biased towards one feature.
Therefore, we scale our data before employing a distance based algorithm so that all the features contribute equally to the result.

The effect of scaling is conspicuous when we compare the Euclidean distance between data points for students A and B, and between B and C, before and after scaling, as shown below:
- Distance AB before scaling =>

- Distance BC before scaling =>

- Distance AB after scaling =>

- Distance BC after scaling =>

Tree-Based Algorithms
Tree-based algorithms, on the other hand, are fairly insensitive to the scale of the features. Think about it, a decision tree only splits a node based on a single feature. The decision tree splits a node on a feature that increases the homogeneity of the node. Other features do not influence this split on a feature.
So, the remaining features have virtually no effect on the split. This is what makes them invariant to the scale of the features!
What is Normalization?
Normalization, a vital aspect of Feature Scaling, is a data preprocessing technique employed to standardize the values of features in a dataset, bringing them to a common scale. This process enhances data analysis and modeling accuracy by mitigating the influence of varying scales on machine learning models.
Normalization is a scaling technique in which values are shifted and rescaled so that they end up ranging between 0 and 1. It is also known as Min-Max scaling.
Here’s the formula for normalization:

Here, Xmax and Xmin are the maximum and the minimum values of the feature, respectively.
- When the value of X is the minimum value in the column, the numerator will be 0, and hence X’ is 0
- On the other hand, when the value of X is the maximum value in the column, the numerator is equal to the denominator, and thus the value of X’ is 1
- If the value of X is between the minimum and the maximum value, then the value of X’ is between 0 and 1
What is Standardization?
Standardization is another Feature scaling method where the values are centered around the mean with a unit standard deviation. This means that the mean of the attribute becomes zero, and the resultant distribution has a unit standard deviation.
Here’s the formula for standardization:
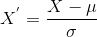
 is the mean of the feature values and
is the mean of the feature values and  is the standard deviation of the feature values. Note that, in this case, the values are not restricted to a particular range.
is the standard deviation of the feature values. Note that, in this case, the values are not restricted to a particular range.
Now, the big question in your mind must be when should we use normalization and when should we use standardization? Let’s find out!
The Big Question – Normalize or Standardize?
| Normalization | Standardization |
|---|---|
| Rescales values to a range between 0 and 1 | Centers data around the mean and scales to a standard deviation of 1 |
| Useful when the distribution of the data is unknown or not Gaussian | Useful when the distribution of the data is Gaussian or unknown |
| Sensitive to outliers | Less sensitive to outliers |
| Retains the shape of the original distribution | Changes the shape of the original distribution |
| May not preserve the relationships between the data points | Preserves the relationships between the data points |
| Equation: (x – min)/(max – min) | Equation: (x – mean)/standard deviation |
However, at the end of the day, the choice of using normalization or standardization will depend on your problem and the machine learning algorithm you are using. There is no hard and fast rule to tell you when to normalize or standardize your data. You can always start by fitting your model to raw, normalized, and standardized data and comparing the performance for the best results.
It is a good practice to fit the scaler on the training data and then use it to transform the testing data. This would avoid any data leakage during the model testing process. Also, the scaling of target values is generally not required.
Implementing Feature Scaling in Python
Now comes the fun part – putting what we have learned into practice. I will be applying feature scaling to a few machine-learning algorithms on the Big Mart dataset. I’ve taken on the DataHack platform.
I will skip the preprocessing steps since they are out of the scope of this tutorial. But you can find them neatly explained in this article. Those steps will enable you to reach the top 20 percentile on the hackathon leaderboard, so that’s worth checking out!
So, let’s first split our data into training and testing sets:
Python Code:
import sys
import subprocess
subprocess.check_call([sys.executable, '-m', 'pip', 'install', 'sklearn'])
import pandas as pd
# spliting training and testing data
from sklearn.model_selection import train_test_split
X = df
y = target
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,random_state=27)Before moving to the feature scaling part, let’s glance at the details of our data using the pd.describe() method:

We can see that there is a huge difference in the range of values present in our numerical features: Item_Visibility, Item_Weight, Item_MRP, and Outlet_Establishment_Year. Let’s try and fix that using feature scaling!
Note: You will notice negative values in the Item_Visibility feature because I have taken log-transformation to deal with the skewness in the feature.
Normalization Using sklearn (scikit-learn)
To normalize your data, you need to import the MinMaxScaler from the sklearn library and apply it to our dataset. So, let’s do that!
# data normalization with sklearn
from sklearn.preprocessing import MinMaxScaler
# fit scaler on training data
norm = MinMaxScaler().fit(X_train)
# transform training data
X_train_norm = norm.transform(X_train)
# transform testing dataabs
X_test_norm = norm.transform(X_test)Let’s see how normalization has affected our dataset:

All the features now have a minimum value of 0 and a maximum value of 1. Perfect!
Try out the above code in the live coding window below!
import pandas as pd
from sklearn.model_selection import train_test_split
# data normalization with sklearn
from sklearn.preprocessing import MinMaxScaler
data = pd.read_csv("train.csv")
print("Big Mart Data")
print(data.columns)
X = data[['Item_Weight', 'Item_MRP']]
y = data['Item_Outlet_Sales']
print(X.head())
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,random_state=27)
# fit scaler on training data
norm = MinMaxScaler().fit(X_train)
# transform training data
X_train_norm = norm.transform(X_train)
print("Scaled Train Data: \n\n")
print(X_train_norm)
# transform testing dataabs
X_test_norm = norm.transform(X_test)
print("\n\nScaled Test Data: \n\n")
print(X_test_norm)Next, let’s try to standardize our data.
Standardization Using sklearn
To standardize your data, you need to import the StandardScaler from the sklearn library and apply it to our dataset. Here’s how you can do it:
# data standardization with sklearn
from sklearn.preprocessing import StandardScaler
# copy of datasets
X_train_stand = X_train.copy()
X_test_stand = X_test.copy()
# numerical features
num_cols = ['Item_Weight','Item_Visibility','Item_MRP','Outlet_Establishment_Year']
# apply standardization on numerical features
for i in num_cols:
# fit on training data column
scale = StandardScaler().fit(X_train_stand[[i]])
# transform the training data column
X_train_stand[i] = scale.transform(X_train_stand[[i]])
# transform the testing data column
X_test_stand[i] = scale.transform(X_test_stand[[i]])You would have noticed that I only applied standardization to my numerical columns, not the other One-Hot Encoded features. Standardizing the One-Hot encoded features would mean assigning a distribution to categorical features. You don’t want to do that!
But why did I not do the same while normalizing the data? Because One-Hot encoded features are already in the range between 0 to 1. So, normalization would not affect their value.
Right, let’s have a look at how standardization has transformed our data:

The numerical features are now centered on the mean with a unit standard deviation. Awesome!
Comparing Unscaled, Normalized, and Standardized Data
It is always great to visualize your data to understand the distribution present. We can see the comparison between our unscaled and scaled data using boxplots.

You can notice how scaling the features brings everything into perspective. The features are now more comparable and will have a similar effect on the learning models.
Applying Scaling to Machine Learning Algorithms
It’s now time to train some machine learning algorithms on our data to compare the effects of different Feature scaling techniques on the algorithm’s performance. I want to see the effect of scaling on three algorithms in particular: K-Nearest Neighbors, Support Vector Regressor, and Decision Tree.
Now, let’s delve into training machine learning algorithms on our dataset to assess the impact of various scaling techniques on their performance. Specifically, I aim to observe the effects of scaling on three key algorithms: K-Nearest Neighbors, Support Vector Regressor, and Decision Tree. This analysis will provide valuable insights into the significance of feature scaling in machine learning and how it influences the outcomes of these algorithms.
K-Nearest Neighbors
As we saw before, KNN is a distance-based algorithm that is affected by the range of features. Let’s see how it performs on our data before and after scaling:
# training a KNN model
from sklearn.neighbors import KNeighborsRegressor
# measuring RMSE score
from sklearn.metrics import mean_squared_error
# knn
knn = KNeighborsRegressor(n_neighbors=7)
rmse = []
# raw, normalized and standardized training and testing data
trainX = [X_train, X_train_norm, X_train_stand]
testX = [X_test, X_test_norm, X_test_stand]
# model fitting and measuring RMSE
for i in range(len(trainX)):
# fit
knn.fit(trainX[i],y_train)
# predict
pred = knn.predict(testX[i])
# RMSE
rmse.append(np.sqrt(mean_squared_error(y_test,pred)))
# visualizing the result
df_knn = pd.DataFrame({'RMSE':rmse},index=['Original','Normalized','Standardized'])
df_knn
You can see that scaling the features has brought down the RMSE score of our KNN model. Specifically, the normalized data performs a tad bit better than the standardized data.
Note: I am measuring the RMSE here because this competition evaluates the RMSE.
Support Vector Regressor
SVR is another distance-based algorithm. So let’s check out whether it works better with normalization or standardization:
# training an SVR model
from sklearn.svm import SVR
# measuring RMSE score
from sklearn.metrics import mean_squared_error
# SVR
svr = SVR(kernel='rbf',C=5)
rmse = []
# raw, normalized and standardized training and testing data
trainX = [X_train, X_train_norm, X_train_stand]
testX = [X_test, X_test_norm, X_test_stand]
# model fitting and measuring RMSE
for i in range(len(trainX)):
# fit
svr.fit(trainX[i],y_train)
# predict
pred = svr.predict(testX[i])
# RMSE
rmse.append(np.sqrt(mean_squared_error(y_test,pred)))
# visualizing the result
df_svr = pd.DataFrame({'RMSE':rmse},index=['Original','Normalized','Standardized'])
df_svr
We can see that scaling the features does bring down the RMSE score. And the standardized data has performed better than the normalized data. Why do you think that’s the case?
The sklearn documentation states that SVM, with RBF kernel, assumes that all the features are centered around zero and variance is of the same order. This is because a feature with a variance greater than that of others prevents the estimator from learning from all the features. Great!
Decision Tree
We already know that a Decision tree is invariant to feature scaling. But I wanted to show a practical example of how it performs on the data:
# training a Decision Tree model
from sklearn.tree import DecisionTreeRegressor
# measuring RMSE score
from sklearn.metrics import mean_squared_error
# Decision tree
dt = DecisionTreeRegressor(max_depth=10,random_state=27)
rmse = []
# raw, normalized and standardized training and testing data
trainX = [X_train,X_train_norm,X_train_stand]
testX = [X_test,X_test_norm,X_test_stand]
# model fitting and measuring RMSE
for i in range(len(trainX)):
# fit
dt.fit(trainX[i],y_train)
# predict
pred = dt.predict(testX[i])
# RMSE
rmse.append(np.sqrt(mean_squared_error(y_test,pred)))
# visualizing the result
df_dt = pd.DataFrame({'RMSE':rmse},index=['Original','Normalized','Standardized'])
df_dt
v
You can see that the RMSE score has not moved an inch on scaling the features. So rest assured when you are using tree-based algorithms on your data!
Build Effective Machine Learning Models
This tutorial covered the relevance of using feature scaling on your data and how normalization and standardization have varying effects on the working of machine learning algorithms. Remember that there is no correct answer to when to use normalization over standardization and vice-versa. It all depends on your data and the algorithm you are using.
Hope you get a clear understanding of how to normalize data and why feature scaling is important in machine learning. You’ll learn simple ways to do feature normalization to improve your models.
To enhance your skills in feature engineering and other key data science techniques, consider enrolling in our Data Science Black Belt program. Our comprehensive curriculum covers all aspects of data science, including advanced topics such as feature engineering, machine learning, and deep learning. With hands-on projects and mentorship, you’ll gain practical experience and the skills you need to succeed in this exciting field. Enroll today and take your data science skills to the next level!
Frequently Asked Questions
Q1. How is Standardization different from Normalization feature scaling?
A. Standardization centers data around a mean of zero and a standard deviation of one, while normalization scales data to a set range, often [0, 1], by using the minimum and maximum values.
Q2. Why is Standardization used in machine learning?
A. Standardization ensures algorithmic stability and prevents sensitivity to the scale of input features, improves optimization algorithms’ convergence and search efficiency, and enhances the performance of certain machine learning algorithms.
Q3. Why is Normalization used in machine learning?
A. Normalization helps in scaling the input features to a fixed range, typically [0, 1], to ensure that no single feature disproportionately impacts the results. It preserves the relationship between the minimum and maximum values of each feature, which can be important for some algorithms. It also improves the convergence and stability of some machine learning algorithms, particularly those that use gradient-based optimization.
Q4. Why do we normalize values?
A. We normalize values to bring them into a common scale, making it easier to compare and analyze data. Normalization also helps to reduce the impact of outliers and improve the accuracy and stability of statistical models.
Q5. How do you normalize a set of values?
A. To normalize a set of values, we first calculate the mean and standard deviation of the data. Then, we subtract the mean from each value and divide by the standard deviation to obtain standardized values with a mean of 0 and a standard deviation of 1. Alternatively, we can use other normalization techniques such as min-max normalization, where we scale the values to a range of 0 to 1, or unit vector normalization, where we scale the values to have a length of 1.
I am on a journey to becoming a data scientist. I love to unravel trends in data, visualize it and predict the future with ML algorithms! But the most satisfying part of this journey is sharing my learnings, from the challenges that I face, with the community to make the world a better place!







Excelent article! Thank you very much for sharing. I have one question. In the post you say: "It is a good practice to fit the scaler on the training data and then use it to transform the testing data.", but I didn't see that in the code you posted. Am I wrong? How would one "fit the scaler on the training data and then use it to transform the testing data"? Thanks a lot again
Hi Ali You fit the scaler on the training data so that it can calculate the necessary parameters, like mean and standard deviation for standardization, and store it for later use using the fit() method. Later you use the transform() function to apply the same transformation on both, train and test dataset. I have used this approach for both, normalization and standardization, in the article in the gists "NormalizationVsStandarization_2.py" and "NormalizationVsStandarization_3.py" respectively. I hope this cleared your doubt. Thanks
Good article! Thank you very much for sharing. I have one question. What the difference between sklearn.preprocessing import MinMaxScaler Normalization and sklearn.preprocessing.Normalizer? When to use MinMaxScaler and when to Normalize?
Hi I hope MinMaxScaler is already clear from the article. Normalizer is also a normalization technique. The only difference is the way it computes the normalized values. By default, it is calculating the l2 norm of the row values i.e. each element of a row is normalized by the square root of the sum of squared values of all elements in that row. As mentioned in the documentation, it is useful in text classification where the dot product of two Tf-IDF vectors gives a cosine similarity between the different sentences/documents in the dataset. Other than that, as I mentioned in the article, there is no sure way to know which scaling technique should be used when. The best way is to create multiple scaled copies of the data and then try them out and see which one gives the best result. Hope this helps.
Excellent article! Easy to understand and good coverage One question: I see that there is a scale() funtion as well from sklearn and short description suggest it to be similar to StandardScaler i.e. scaling to unit variance I could not find more than this explanation. Please can you suggest which on to use which scenario? Thanks in advance!
Hi Subhash I notice two differences between the two functions. First was that the scale() function allows you to standardize your data along any axis. This means that you could even standardize your data row-wise as opposed to feature-wise, which is what happens in StandardScaler(). Second difference was that the scale function has no fit and transform methods, so you cannot apply the same scaling to your test dataset. I would suggest using the StandardScaler() function as I have never used the scale() personally. I hope this helps!