Introduction
“Data is the new oil” is a common saying nowadays in the areas of marketing, medical science, economics, finance, any research field, and the IT industry. The significance of oil is derived from the fact that oil companies have been ruling the globe for decades. Major global tension has its base in the form of oil.
The areas where data synonymize with oil are both fuel economy, oil fuels industrial economy whereas data fuels information economy; both have given transportation a new dimension, oil led to the development of engine-based transportation system and data are leading towards the auto-transportation system, and both give rise to meaningful products, oil gives energy and data gives information. However, there exist differences between oil and data too. Oil has limited availability, data is available in abundance, and oil being a tangible product has an associated cost, data has no such associated cost as it is a non-tangible product (Adesina, 2018).
New Oil, i.e., Data is a collection of numbers, words, events, facts, measurements, and observations. The data after processing gives us information. The information leads to useful knowledge. A challenging task is to process these data into information and EDA (Exploratory data analysis) is the solution to that challenge (Mukhiya & Ahmed, 2020).
Exploratory Data Analysis
EDA is a process through which an available dataset is examined to discover patterns, detect any irregularities, test hypotheses, and statistically analyze assumptions. The main purpose of EDA is to understanding what the given data tells before modeling or formulating hypotheses. EDA was promoted by John Tuckey to statisticians (Mukhiya & Ahmed, 2020).
Contemplating data requirements, data collection, data processing, and data cleaning are the stages that precede EDA. An appropriate decision needs to be made from the data collected about different fields which are primary stored in electronic databases. Data mining is the process that gives an insight into the raw data and EDA forms the first stage of Data mining.
Different approaches towards data analysis
There are several approaches for data analysis and a glimpse of three important approaches viz. classical data analysis, Exploratory data analysis, and Bayesian data analysis approach are shown in the following figure
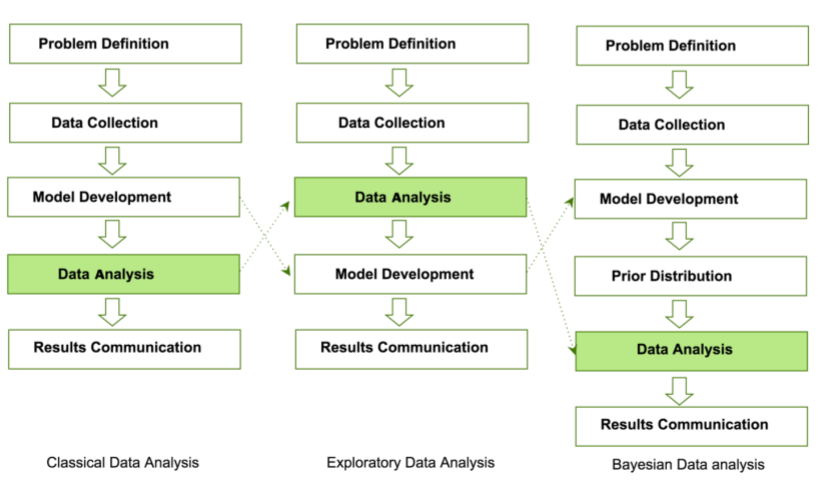
Fig 1: 3 important approaches of data analysis
Courtesy: Mukhiya & Ahmed, 2020
Stages of EDA
After discussing in brief, the precursors, and significance of EDA along with a comparative analysis of other approaches of data exploration, it is important to understand the stages of data exploration. Mukhiya & Ahmed, 2020 put forth the four different stages of EDA which are-
1. Definition of the problem – To define a problem, it is important to define the primary objective of the analysis alongside defining main deliverables, roles, and responsibilities, the present state of the data, setting a timeline, and analyzing the cost to benefit ratio.
2. Preparation of data – In this stage, characteristics of data are being comprehended, the dataset is cleaned, and irrelevant data are deleted.
3. Analyzing the data – In this stage, the data are being summarized, hidden correlations are being derived, predictive models are being developed and evaluated, and summary tables are being generated.
4. Results representation – Finally, the dataset is being presented to the target audience in the form of graphs, and summary tables.
Explanation of EDA using a sample dataset
Agriculture is one of the most important sectors of the Indian Economy. Here, we would be performing an EDA using a small agricultural dataset apy.csv step by step.
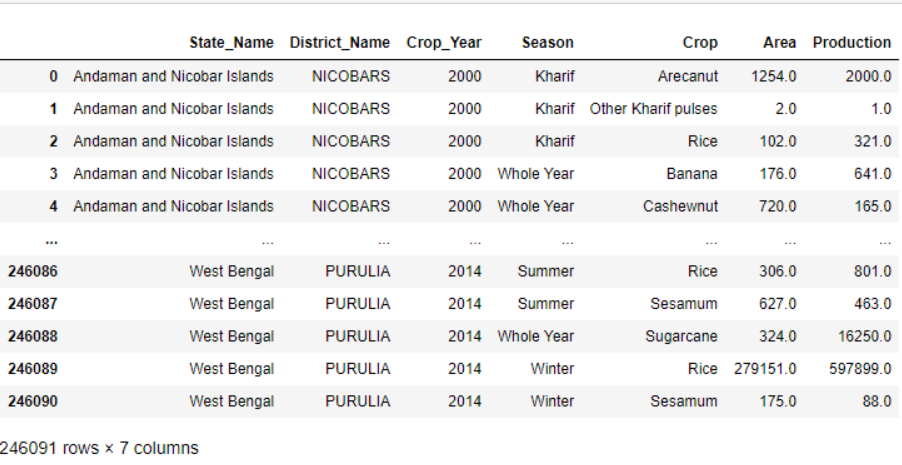
First, let’s import pandas and NumPy libraries where ‘pandas’ library is used to work with data frames and ‘NumPy’ library performs the numerical operation. Then, the dataset is read. If we write ‘data’, it would give a snapshot of all the rows and columns present in the dataset whereas data.head() function displays top 5 rows.
import pandas as pd
import numpy as np
data = pd.read_csv('apy.csv')
data
data.head()
Now, we make a copy of the original data. There are 2 ways to create copies in python which are shallow and deep copy.
In the case of a shallow copy, the original object gets changed if any changes are being made to the copy whereas, in the case of a deep copy, no such changes happen as there is no reference to the original object.
By default, it is true. Then, we find information about the data. It is pertinent to mention that ‘dataframe.tail()’ displays the last 5 rows.
datacopy=data.copy() datacopy.head()
datacopy.tail()
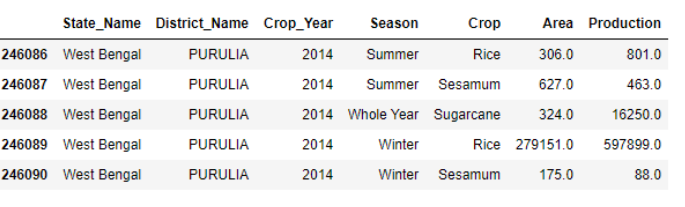
datacopy.info()
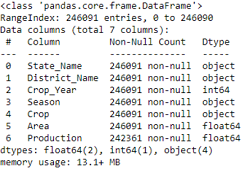
By using .info (), we gather information on the datatypes of various columns of the dataset, memory usage, and non-null count. Now, we shall remove the redundant columns and rows. We shall check the count of
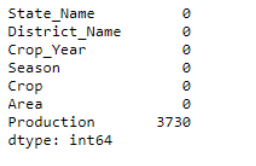
missing values through the .isnull().sum() function and store all the information
in a new dataframe ‘Data’.
datacopy.isnull().sum()
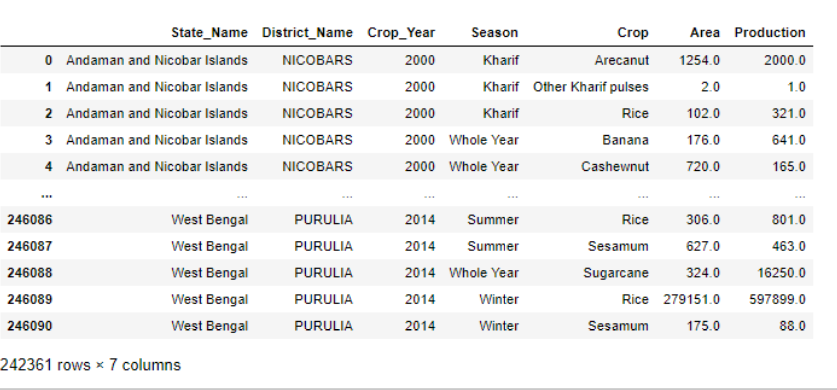
Data=datacopy.dropna(axis=0)
Data
Data.isnull().sum()
Let us perform some statistical operations in the data about the production, let us find the average and the standard deviation of the production
Data['Production'].mean()
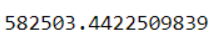
Data['Production'].std()
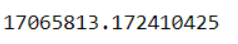
Now, let us try to extract further information from the dataset. Here, we shall try to find out the following-
- State having highest area of production
- State in India having lowest crop production
- The correlation coefficient between Area and Production
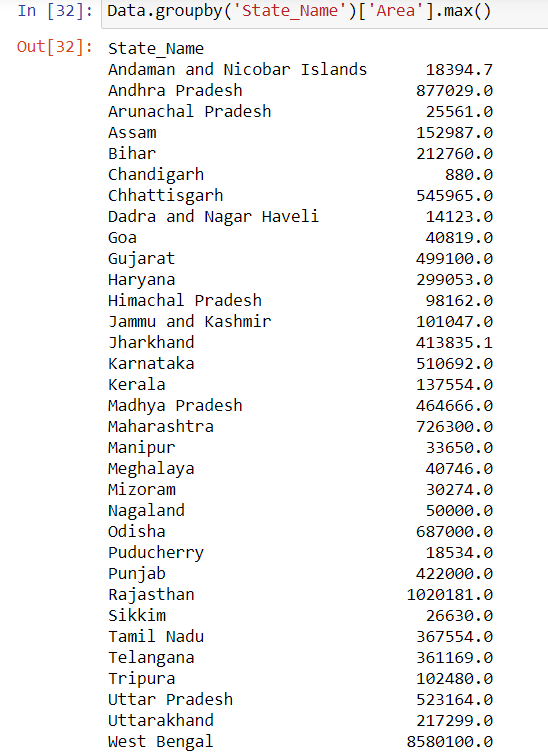
State having highest area of production
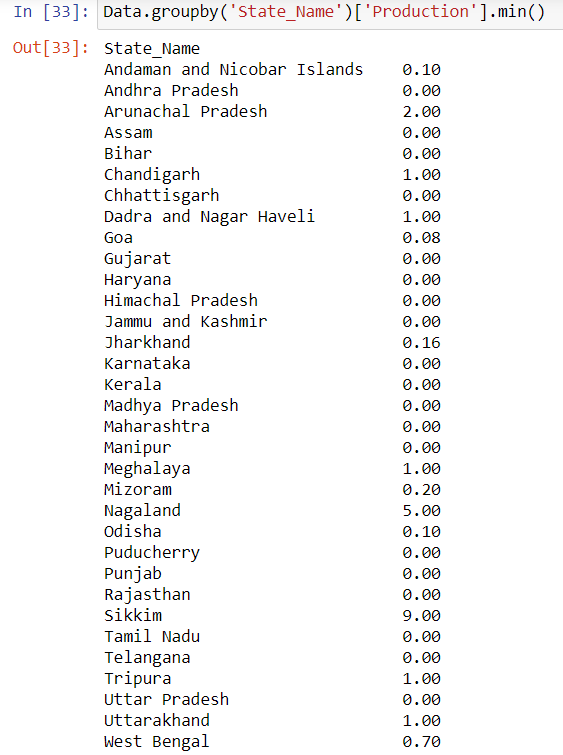
State in India having lowest crop production
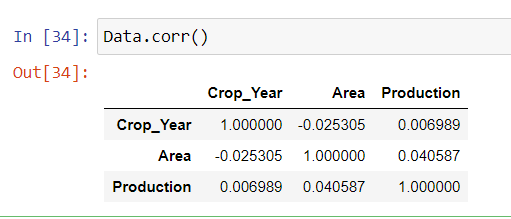
The correlation coefficient between Area and Production
Dataset can also be described by using .describe() function. It gives a summary of the data. The summary comprises mean, count, standard deviation, median (50%), range (max-min), and IQR, Interquartile range (Q3-Q1) where Q3 corresponds to 75% and Q1 corresponds to 25%.
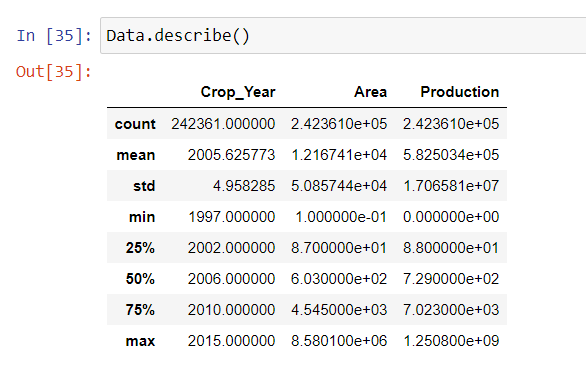
With the help of python, essential information can be obtained from the dataset which enables policymakers to implement better policies for farmers. EDA helps in achieving this objective. Describe aspect helps in understanding various statistical measures of data.
Conclusion
EDA forms the base of data mining. The stages and various methodologies explained in this article are the basics of EDA.
The succeeding stages are data visualization and modeling where data visualization involves importing libraries like seaborn and matplotlib and that of modeling involves importing train_test_split from sklearn.model_selection and many others.
A book Hands-on Exploratory Data Analysis with Python is recommended for the readers to further delve into the subject. Hopefully, this article would be found useful for beginner and intermediate level data science enthusiasts.
References
1. Adesina, A. (2018). Data is the new oil. Retrieved from https://medium.com/@adeolaadesina/data-is-the-new-oil-2947ed8804f6
2. Mukhiya, S, K., & Ahmed, U. (2020). Hands-on Exploratory Data Analysis with Python. Mumbai: Packt.
I am a biotechnology graduate with experience in Administration, Research and Development, Information Technology & management, and Academics of more than 12 years. I have experience of working in organizations like Ranbaxy, Abbott India Limited, Drivz India, LIC, Chegg, Expertsmind, and Coronawhy.
Recognition:
1. Played major role in making a brand “Duphaston” worth “Rs 100 crores INR” in Abbott India Limited as Therapy Business Manager of Women’s health and gastro intestine team.
2. Won “best marketing skills” award in Abbott India Limited.
3. Came on the merit list of National IT aptitude test, 2010.
4. Represented my school in regional social science exhibition.
Courses and Trainings:
1. Took 54 hours training on vb.net in Niit, Guwahati.
2. Underwent training of 7 days on targeting and segmentation in Abbott India ltd, Lonavala.
3. Earned “Elite Certificate” from IIT-Madras on “Python for Data Science”.






