This article was published as a part of the Data Science Blogathon
Agenda
We have all built a logistic regression at some point in our lives. Even if we have never built a model, we have definitely learned this predictive model technique theoretically. Two simple, undervalued concepts used in the preprocessing step to build a logistic regression model are the weight of evidence and information value. I would like to bring them back to the limelight through this article.
This article is structured in the following way:
- Introduction to logistic regression
- Importance of feature selection
- Need for a good imputer for categorical features
- WOE
- IV
Let’s get started!
1. Introduction to Logistic Regression
First thing first, we all know logistic regression is a classification problem. In particular, we consider binary classification problems here.
Logistic regression models take as input both categorical and numerical data and output the probability of the occurrence of the event.
Example problem statements that can be solved using this method are:
- Given the customer data, what is the probability that the customer will buy a new product introduced by a company?
- Given the required data, what is the probability that a bank customer will default on a loan?
- Given the weather data for the last one month, what is the probability that it will rain tomorrow?
All the above statements had two outcomes. (buy & not buy, default & not default, rain & not rain). Hence a binary logistic regression model can be built. Logistic regression is a parametric method. What does this mean? A parametric method has two steps.
1. First, we assume a functional form or shape. In the case of logistic regression, we assume that
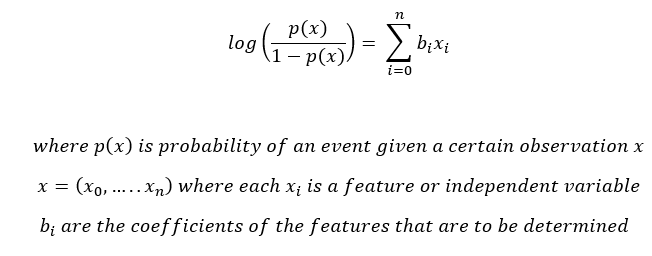
2. We need to predict the weights/coefficients bi such that, the probability of an event for an observation x is close to 1 if the actual value of the target is 1 and the probability is close to 0 if the actual value of the target is 0.
With this basic understanding, let us understand why do we need feature selection.
2. Importance of Feature Selection
In this digital era, we are equipped with a humongous amount of data. However, not all features available to us are useful in every model prediction. We have all heard the saying “Garbage in, garbage out!”. Hence, choosing the right features for our model is of utmost importance. Features are selected based on the predictive strength of the feature.
For instance, let us say we want to predict the probability that a person will buy a new Chicken recipe at our restaurant. If we have a feature – “Food preference” with values {Vegetarian, Non-Vegetarian, Eggetarian}, we are almost certain that this feature will clearly separate people who have a higher probability of buying this new dish from those who will never buy it. Hence this feature has high predictive power.
We can quantify the predictive power of a feature using the concept of information value that will be described here.
3. Need for a good imputer for categorical features
Logistic regression is a parametric method that requires us to calculate a linear equation. This requires that all features are numerical. However, we might have categorical features in our datasets that are either nominal or ordinal. There are many methods of imputation like one-hot encoding or simply assigning a number to each class of categorical features. each of these methods has its own merits and demerits. However, I will not be discussing the same here.
In the case of logistic regression, we can use the concept of WoE (Weight of Evidence) to impute the categorical features.
4. Weight of Evidence
After all the background provided, we have finally arrived at the topic of the day!
The formula to calculate the weight of evidence for any feature is given by
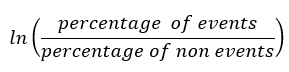
Before I go ahead explaining the intuition behind this formula, let us take a dummy example:
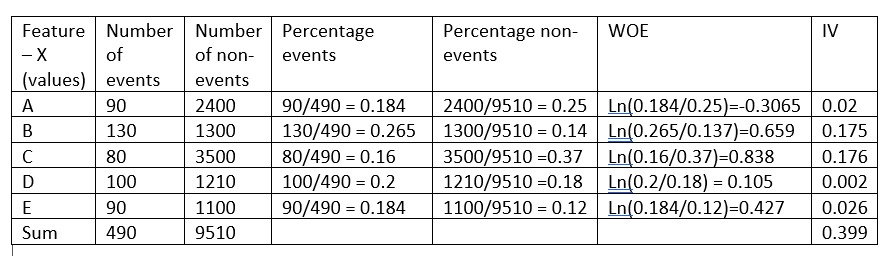
The weight of evidence tells the predictive power of a single feature concerning its independent feature. If any of the categories/bins of a feature has a large proportion of events compared to the proportion of non-events, we will get a high value of WoE which in turn says that that class of the feature separates the events from non-events.
For example, consider category C of the feature X in the above example, the proportion of events (0.16) is very small compared to the proportion of non-events(0.37). This implies that if the value of the feature X is C, it is more likely that the target value will be 0 (non-event). The WoE value only tells us how confident we are that the feature will help us predict the probability of an event correctly.
Now that we know that WoE measures the predictive power of every bin/category of a feature, what are the other benefits of WoE?
1. WoE values for the various categories of a categorical variable can be used to impute a categorical feature and convert it into a numerical feature as a logistic regression model requires all its features to be numerical.
On careful examination of the formula of WoE and the logistic regression equation to be solved, we see that the WoE of a feature has a linear relationship with the log odds. This ensures that the requirement of the features having linear relation with the log odds is satisfied.
2. For the same reason as above, if a continuous feature does not have a linear relationship with the log odds, the feature can be binned into groups and a new feature created by replaced each bin with its WoE value can be used instead of the original feature. Hence WoE is a good variable transformation method for logistic regression.
3. On arranging a numerical feature in ascending order, if the WoE values are all linear, we know that the feature has the right linear relation with the target, However, if the feature’s WoE is non-linear, we should either discard it or consider some other variable transformation to ensure the linearity. Hence WoE gives us a tool to check for the linear relationship with the dependent feature.
4. WoE is better than one-hot encoding as one-hot encoding will need you to create h-1 new features to accommodate one categorical feature with h categories. This implies that the model will not have to predict h-1 coefficients (bi) instead of 1. However, in WoE variable transformation, we will need to calculate a single coefficient for the feature in consideration.
5. Information Value
Having discussed the WoE value, the WoE value tells us the predictive power of each bin of a feature. However, a single value representing the entire feature’s predictive power will be useful in feature selection.
The equation for IV is
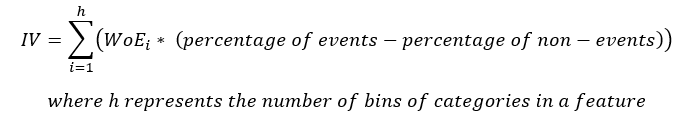
Note that the term (percentage of events – the percentage of non-events) follows the same sign as WoE hence ensuring that the IV is always a positive number.
How do we interpret the IV value?
The table below gives you a fixed rule to help select the best features for your model
| Information Value | Predictive power |
| <0.02 | Useless |
| 0.02 to 0.1 | Weak predictors |
| 0.1 to 0.3 | Medium Predictors |
| 0.3 to 0.5 | Strong predictors |
| >0.5 | Suspicious |
As seen from the above example, feature X has an information value of 0.399 which makes it a strong predictor and hence will be used in the model.
6. Conclusion
As seen from the above example, the calculation of the WoE and IV are beneficial and help us analyze multiple points as listed below
1. WoE helps check the linear relationship of a feature with its dependent feature to be used in the model.
2. WoE is a good variable transformation method for both continuous and categorical features.
3. WoE is better than on-hot encoding as this method of variable transformation does not increase the complexity of the model.
4. IV is a good measure of the predictive power of a feature and it also helps point out the suspicious feature.
Though WoE and IV are highly useful, always ensure that it is only used with logistic regression. Unlike other feature selection methods available, the features selected using IV might not be the best feature set for a non-linear model building.
Hope this article has helped you gain intuition into the workings of WoE and IV.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.







In the chart above, woe for the category C would be -0.843
Why are you showing only positive woe?