This article was published as a part of the Data Science Blogathon.
Introduction
The Titanic ship disaster is one of the most infamous shipwrecks. The luxury cruiser, touted to be one of the safest when launched, sank thousands of passengers due to an accident with an iceberg. Out of 2224 passengers, 1502 passengers died due to the shipwreck. The accident had made some researchers wonder what could have led to the survival of some and the demise of others. Could there be identifiable reasons with regard to why some people died while some others survived?
Let’s Dig Deeper!
The passenger data of the titanic ship has somehow been made into a public dataset and has been frequently used for introducing and teaching machine learning. But how relevant is the titanic dataset for machine learning? Does the titanic dataset help a beginner to learn the fundamentals of machine learning easier and faster? There are many articles, blogs and courses that use Titanic Dataset for introducing machine learning to beginners.
I believe that it is wrong to use the titanic dataset to understand the workings of machine learning. In fact, the titanic dataset can better be used to learn what machine learning is NOT and how and where it should NOT be used. Because of this reason, it is not advisable to introduce machine learning with the titanic dataset.
1. Applicability and Reproducibility of the Model
A machine learning model should be reproducible, replicable, and applicable in similar situations. Reproducibility of a machine learning model means the ability to use the same computational procedures, data, and tools to obtain similar results. It would be possible to reproduce the model if it proves to be valid for similar datasets from the same population. For the titanic case, the population can be considered to be people travelling through luxury cruisers. The titanic dataset is one sample from the above population.
If the relationships under the model from a sample dataset are spurious, then it cannot be reproduced and applied to similar real-world conditions. For example, the machine learning model using the titanic dataset should be applicable for any luxury cruiser. Suppose today there exists a luxury cruiser similar to titanic, can we apply this model to find out who will survive or die if that cruiser meets with a similar accident? If we can get some insights of this kind, then we can screen passengers before travel, using the model, and initiate risk mitigation plans.
Of course, the titanic dataset is used only for training and understanding purposes, but the underlying principles of machine learning should not be lost. It is important to give importance to training datasets used for introducing the topic of machine learning
2. Machine Learning and the Relationship Between Features and the Target Variable
Machine learning models should not be treated as a black box without understanding how they make predictions. Though this is where the traditional statistical models differ from algorithmic models, it is necessary at least to understand from the perspective of the features that are used to make predictions. Identifying the features that are relevant to the problem on hand is the first step before analyzing how they are related to the variable to be predicted.
In the case of the titanic dataset, the important question for a machine learning analyst is to determine which of the variables make an impact on the survivorship as against determining the accuracy of the final prediction based on some model. How important is the variable ‘passenger class’ compared to ‘lifeboat’ or sex in survivorship? How did the number of lifeboats or their nearness to the passengers help the survivorship? The feature set selected for the analysis should take into account all these considerations. The titanic dataset is just passenger data collected before boarding and has nothing to do with the possible accidents or consequent survivorship.
In the last section of this article, I shall explain more about this. More specifically, the hypothesis that explains the survivorship is found to be the possible dictum issued before evacuation that “Women and Children First” as part of the evacuation procedure. I don’t find even this insight in any of the blogs and articles that use the Titanic dataset for teaching machine learning.
Insights derived from the machine learning model should go far beyond the insights that can be obtained from exploratory data analysis and should facilitate predictions when deployed in the production environment.
3. Machine learning is not all About Accuracy
A machine learning model, done without an analysis of the relationship between various features and target variables, and assumptions behind the model chosen, may give high accuracy but that accuracy measure need not necessarily imply a strong relationship between the feature set and the target variable as against a statistical model like linear regression where inferential statistics can validate the model results.
The data available in the titanic dataset are not helpful in this regard. If we can unearth the real variables that determine survivorship, then we can take extra care while building any new luxury cruiser so that percentage of survivorship can be increased. This is the main application of machine learning models and not just the accuracy measure.
Suppose a telecom company finds high volatility in customer accretion. Many customers seem to purchase the telecom product but also leave frequently without any identifiable cause. If a machine learning model is used to analyze the pattern and unearth the causes behind the volatility, it should also help build better products and perform efficient customer management. It is not just only about predicting which customer is likely to remain or leave.
4. Model Building
While building the machine learning models, the initial focus should be to select the feature set that is applicable for the target variable. In the case of the titanic dataset, the data pertains to routine passenger data collected which has nothing to do with accident or survivorship.
In the case of the titanic dataset, choosing some three variables viz., sex, parents, and children & siblings, we get an accuracy of 78.7%. Can we predict for any current luxury cruiser, the survivorship, based only on these three variables, with 78% accuracy? Can we get meaningful insights that are applicable to the entire population of luxury cruisers? The titanic dataset is simply not collected for this purpose.
Similarly, there are also several other public datasets that are used for learning machine learning that does not have features that are anywhere relevant to the predicted target variable. Two examples are the widely floating around datasets viz., telecom customer churn and customer loan prediction. Many of the publicly available datasets on these two areas have features that have no relevance to the actual predictions to be made.
While building the machine learning model, we should first check the relevance of the feature set for making the predictions of the target variable. Once we understand the variables and validate the model, we can construct our business models and processes to utilize these machine learning insights.
5. Why Titanic Dataset?
Before I conclude this article, I shall highlight some points as to why, first of all, titanic dataset could have been chosen for machine learning training. There are some reasons but they are not sufficient reasons for using it for machine learning.
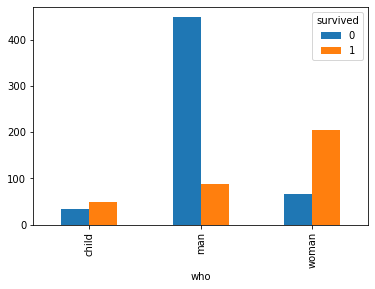
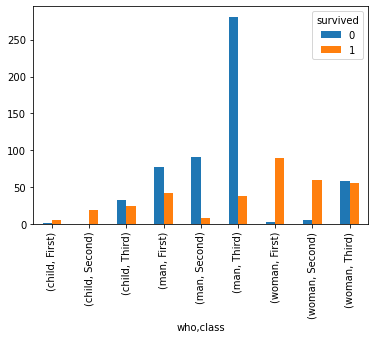
1. Titanic disaster is an accident. In an accident, we would expect survivorship to be random – those who survived would have done it mostly by luck. But in the case of titanic, the survivorship was not random. Here are some facts:
a) Among the survivors, third-class children outnumbered first-class children by a ratio of more than four to one
b) More men survived than women
c) More than twice as many second-class men survived as first-class children
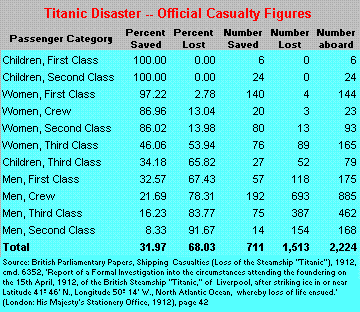
The above data intrigued the analysts and further exploratory data analysis resulted in the following insights (an inquiry was commissioned and the investigation resulted in Lord Mersey’s report). The following sample insights are actually in contrast to the partial facts given above:
a) Though we would expect more men to survive, in the case of Titanic, the survival rate of men was just 20% whereas for women it was 74%.
b) If we go by general common sense that survival rate would be determined by variables like sex, age and class, then compared to this expectation, it was found that survival of first-class passengers was 39.80% more than the expectation while it was 30.58% less than expected for the third class passengers
This kind of insight made investigators analyze how this had come to happen. What are the variables that resulted in this kind of survival pattern?
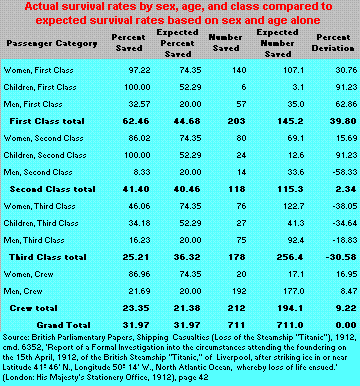
A hypothesis was made that the evacuation procedures involved a dictum that “Women and Children First”, when it was found by the Captain that the lifeboats were not sufficient (enough only for 53% of passengers) in numbers to save all. The analysis of the titanic dataset shows that this was indeed true!
However, all the above insights can be derived from the exploratory data analysis without the use of any machine learning algorithm.
There were still many other theories and hypotheses that tried to explain the survival data. For example, one hypothesis goes like this: “a first-class woman who embarked from Cherbourg had a much better chance of surviving than a third-class man from Southampton”. This hypothesis gives importance to three variables sex, class and embarked station. Several other theories can be formulated to explain the data.
It is true that machine learning can be used to test these theories. For example, we can build a decision tree model using the above three variables alone and check the accuracy of the prediction.
But the purpose of machine learning is not to do a one-off exercise to understand a dataset. Based on exploratory data analysis, we may find a pattern which we might want to test. We can test the validity of such a pattern using a machine learning model. But if the pattern is validated, it should be possible to build that into the machine learning model for decision making. Machine learning models are meant to be deployed in the production environment to help arrive at decisions.
The titanic dataset could be fun to apply the machine learning model to but it does not bring forth the real utility of machine learning as explained in the previous paragraphs.
Conclusion
The titanic dataset has been used as a primer for teaching machine learning to beginners, promoted even by Kaggle. However, using the titanic dataset to teach and understand machine learning can lead to several misconceptions for beginners about the principles underlying the building of true machine learning models. Here are some important principles not emphasized by the use of datasets like Titanic:
1. Machine learning models are meant to solve business problems and help in decision-making. They are not meant to be used as a one-off exercise to gain insights
2. Machine learning models are meant to be reproducible, replicable and applicable in similar contexts. For example, the variables that affect customer churning in one telecom company is not going to be greatly different from another telecom company for a given equivalent product, though they won’t be identical. In this context, Titanic is a sample of the population of passengers who travel in luxury cruisers
3. Machine learning models should focus on understanding the variables or feature sets that influence the decision making, the relationship between them. These are the insights that help in business decision making
4. Accurate predictions and measures of accuracy should not be the driving force behind building machine learning models.
5. The machine learning models should reflect the nature of the business problem at hand and the dataset should reflect the same.
These are a few of the important underlying principles of building machine learning models. These are not sufficiently emphasized when we use datasets like Titanic to understand machine learning
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Finance (MBA,CFA) and IT industry professional with more than 12 years of experience in leading engineering, banking and IT companies in the areas like core banking, ERP, supply chain, implementation consulting, project management, test management, presales etc





